.clangd
.venv/
+ggml_env/
.exrc
.cache
.DS_Store
--- /dev/null
+data/
+*.gguf
+*.ggml
#
-# mnist
+# mnist-common
-set(TEST_TARGET mnist)
-add_executable(${TEST_TARGET} main.cpp)
+set(TEST_TARGET mnist-common)
+add_library(${TEST_TARGET} mnist-common.cpp)
target_link_libraries(${TEST_TARGET} PRIVATE ggml common)
#
-# mnist-cnn
+# mnist-eval
-set(TEST_TARGET mnist-cnn)
-add_executable(${TEST_TARGET} main-cnn.cpp)
-target_link_libraries(${TEST_TARGET} PRIVATE ggml common)
+set(TEST_TARGET mnist-eval)
+add_executable(${TEST_TARGET} mnist-eval.cpp)
+target_link_libraries(${TEST_TARGET} PRIVATE ggml common mnist-common)
#
-# mnist-cpu
-
-set(TEST_TARGET mnist-cpu)
-add_executable(${TEST_TARGET} main-cpu.cpp)
-target_link_libraries(${TEST_TARGET} PRIVATE ggml)
-
-if (APPLE)
- #
- # mnist-mtl
-
- find_library(FOUNDATION_LIBRARY Foundation REQUIRED)
- find_library(METAL_FRAMEWORK Metal REQUIRED)
- find_library(METALKIT_FRAMEWORK MetalKit REQUIRED)
- find_library(METALPERFORMANCE_FRAMEWORK MetalPerformanceShaders REQUIRED)
+# mnist-train
- set(TEST_TARGET mnist-mtl)
- add_executable(${TEST_TARGET} main-mtl.cpp main-mtl.h main-mtl.m)
- target_link_libraries(${TEST_TARGET} PRIVATE
- ggml
- ${FOUNDATION_LIBRARY}
- ${METAL_FRAMEWORK}
- ${METALKIT_FRAMEWORK}
- ${METALPERFORMANCE_FRAMEWORK}
- )
-endif()
+set(TEST_TARGET mnist-train)
+add_executable(${TEST_TARGET} mnist-train.cpp)
+target_link_libraries(${TEST_TARGET} PRIVATE ggml common mnist-common)
# MNIST Examples for GGML
-These are simple examples of how to use GGML for inferencing.
-The first example uses convolutional neural network (CNN), the second one uses fully connected neural network.
+This directory contains simple examples of how to use GGML for training and inference using the [MNIST dataset](https://yann.lecun.com/exdb/mnist/).
+All commands listed in this README assume the working directory to be `examples/mnist`.
+Please note that training in GGML is a work-in-progress and not production ready.
-## MNIST with CNN
+## Obtaining the data
-This implementation achieves ~99% accuracy on the MNIST test set.
+The data can either be downloaded [here](https://yann.lecun.com/exdb/mnist/) or it will be downloaded automatically when running `mnist-train-fc.py`.
-### Training the model
+## Fully connected network
-Setup the Python environemt and build the examples according to the main README.
-Use the `mnist-cnn.py` script to train the model and convert it to GGUF format:
+For our first example we will train a fully connected network.
+To train a fully connected model in PyTorch and save it as a GGUF file, run:
```bash
-$ python3 ../examples/mnist/mnist-cnn.py train mnist-cnn-model
+$ python3 mnist-train-fc.py mnist-fc-f32.gguf
+
...
-Keras model saved to 'mnist-cnn-model'
-```
-Convert the model to GGUF format:
+Test loss: 0.069983+-0.009196, Test accuracy: 97.94+-0.14%
-```bash
-$ python3 ../examples/mnist/mnist-cnn.py convert mnist-cnn-model
-...
-Model converted and saved to 'mnist-cnn-model.gguf'
+Model tensors saved to mnist-fc-f32.gguf:
+fc1.weight (500, 784)
+fc1.bias (500,)
+fc2.weight (10, 500)
+fc2.bias (10,)
```
-### Running the example
+The training script includes an evaluation of the model on the test set.
+To evaluate the model using GGML, run:
```bash
-$ ./bin/mnist-cnn mnist-cnn-model.gguf ../examples/mnist/models/mnist/t10k-images.idx3-ubyte
-main: loaded model in 5.17 ms
-_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ * * * * * _ _ _ _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ _ _ _ * * * * * * * * _ _ _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ _ * * * * * _ _ _ * * _ _ _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ _ * * _ _ _ _ _ _ _ _ _ _ _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _ _ _ _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _ * _ _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _ * * _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _ * * _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ _ * * * _ _ _ _ * * * * * _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ _ * * * * * * * * * _ _ _ _ _ _ _
-_ _ _ _ _ _ _ _ * * * * * * * * * * _ _ _ _ _ _ _ _ _ _
-_ _ _ _ _ _ _ * * * * * * _ _ * * * _ _ _ _ _ _ _ _ _ _
-_ _ _ _ _ _ * * * _ _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _ _
-_ _ _ _ _ _ * * _ _ _ _ _ _ _ _ _ * * _ _ _ _ _ _ _ _ _
-_ _ _ _ _ _ * * _ _ _ _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _
-_ _ _ _ _ _ * * _ _ _ _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _
-_ _ _ _ _ _ * * * _ _ _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _
-_ _ _ _ _ _ _ _ * * * _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _
-_ _ _ _ _ _ _ _ _ * * * * * * * * * * _ _ _ _ _ _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ * * * * * * _ _ _ _ _ _ _ _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
-_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
-
-ggml_graph_dump_dot: dot -Tpng mnist-cnn.dot -o mnist-cnn.dot.png && open mnist-cnn.dot.png
-main: predicted digit is 8
+$ ../../build/bin/mnist-eval mnist-fc-f32.gguf data/MNIST/raw/t10k-images-idx3-ubyte data/MNIST/raw/t10k-labels-idx1-ubyte
+
+________________________________________________________
+________________________________________________________
+________________________________________________________
+________________________________________________________
+________________________________######__________________
+____________________________########____________________
+________________________########________________________
+____________________########________________##__________
+__________________######____________________##__________
+________________######______________________####________
+______________######________________________####________
+____________######__________________________####________
+____________####____________________________####________
+__________####______________________________####________
+__________####______________________________####________
+__________##________________________________####________
+__________##______________________________####__________
+__________##____________________________######__________
+__________##__________________________######____________
+____________##____________________########______________
+____________##########################__________________
+______________##################________________________
+________________________________________________________
+________________________________________________________
+________________________________________________________
+________________________________________________________
+________________________________________________________
+________________________________________________________
+mnist_graph_eval: trying to load a ggml graph from mnist-fc-f32.gguf
+ggml_graph_import: invalid magic number, got 46554747
+mnist_graph_eval: could not load a ggml graph from mnist-fc-f32.gguf
+mnist_model_init_from_file: loading model weights from 'mnist-fc-f32.gguf'
+mnist_model_init_from_file: model arch is mnist-fc
+mnist_model_init_from_file: successfully loaded weights from mnist-fc-f32.gguf
+main: loaded model in 1.52 ms
+mnist_model_eval: model evaluation on 10000 images took 26.65 ms, 2.66 us/image
+main: predicted digit is 0
+main: test_loss=0.069983+-0.009196
+main: test_acc=97.94+-0.14%
```
-Computation graph:
+In addition to the evaluation on the test set the GGML evaluation also prints a random image from the test set as well as the model prediction for said image.
+To train a fully connected model using GGML run:
-
-
-## MNIST with fully connected network
-
-A fully connected layer + relu, followed by a fully connected layer + softmax.
-
-### Training the Model
+``` bash
+$ ../../build/bin/mnist-train mnist-fc mnist-fc-f32.gguf data/MNIST/raw/train-images-idx3-ubyte data/MNIST/raw/train-labels-idx1-ubyte
+```
-A Google Colab notebook for training a simple two-layer network to recognize digits is located here. You can
-use this to save a pytorch model to be converted to ggml format.
+It can then be evaluated with the same binary as above.
+When training a model with GGML the computation graph for the forward pass is also exported to `mnist-fc-f32.ggml`.
+Compared to the GGUF (which only contains the weights) this file also contains the model architecture.
+As long as the input and output tensors are well-defined an exported GGML graph is fully agnostic w.r.t. the model architecture.
+It can be evaluated using the `mnist-eval` binary by substituting the argument for the GGUF file.
-[Colab](https://colab.research.google.com/drive/12n_8VNJnolBnX5dVS0HNWubnOjyEaFSb?usp=sharing)
+## Convolutional network
-GGML "format" is whatever you choose for efficient loading. In our case, we just save the hyperparameters used
-plus the model weights and biases. Run convert-h5-to-ggml.py to convert your pytorch model. The output format is:
+To train a convolutional network using TensorFlow run:
-- magic constant (int32)
-- repeated list of tensors
-- number of dimensions of tensor (int32)
-- tensor dimension (int32 repeated)
-- values of tensor (int32)
+```bash
+$ python3 mnist-train-cnn.py mnist-cnn-f32.gguf
-Run ```convert-h5-to-ggml.py mnist_model.state_dict``` where `mnist_model.state_dict` is the saved pytorch model from the Google Colab. For
-quickstart, it is included in the mnist/models directory.
+...
-```bash
-mkdir -p models/mnist
-python3 ../examples/mnist/convert-h5-to-ggml.py ../examples/mnist/models/mnist/mnist_model.state_dict
+Test loss: 0.046456
+Test accuracy: 98.40%
+GGUF model saved to 'mnist-cnn-f32.gguf'
```
-### Running the example
+The saved model can be evaluated using the `mnist-eval` binary:
```bash
-./bin/mnist ./models/mnist/ggml-model-f32.bin ../examples/mnist/models/mnist/t10k-images.idx3-ubyte
+$ ../../build/bin/mnist-eval mnist-fc-f32.gguf data/MNIST/raw/t10k-images-idx3-ubyte data/MNIST/raw/t10k-labels-idx1-ubyte
+
+________________________________________________________
+________________________________________________________
+________________________________________________________
+________________________________________________________
+________________________________________________________
+________________________________________________________
+________________________________________________________
+________________________####____________________________
+__________________________##____________________________
+__________________________##____________________________
+__________________________##____________________________
+__________________________##____________________________
+__________________________##____________________________
+____________________________##__________________________
+____________________________##__________________________
+____________________________##__________________________
+______________________________##________________________
+______________________________##________________________
+______________________________####______________________
+________________________________##______________________
+________________________________##______________________
+________________________________####____________________
+__________________________________##____________________
+________________________________##______________________
+________________________________________________________
+________________________________________________________
+________________________________________________________
+________________________________________________________
+mnist_graph_eval: trying to load a ggml graph from mnist-cnn-f32.gguf
+ggml_graph_import: invalid magic number, got 46554747
+mnist_graph_eval: could not load a ggml graph from mnist-cnn-f32.gguf
+mnist_model_init_from_file: loading model weights from 'mnist-cnn-f32.gguf'
+mnist_model_init_from_file: model arch is mnist-cnn
+mnist_model_init_from_file: successfully loaded weights from mnist-cnn-f32.gguf
+main: loaded model in 5.45 ms
+mnist_model_eval: model evaluation on 10000 images took 605.60 ms, 60.56 us/image
+main: predicted digit is 1
+main: test_loss=0.046456+-0.007354
+main: test_acc=98.40+-0.13%
```
-Computation graph:
+Like with the fully connected network the convolutional network can also be trained using GGML:
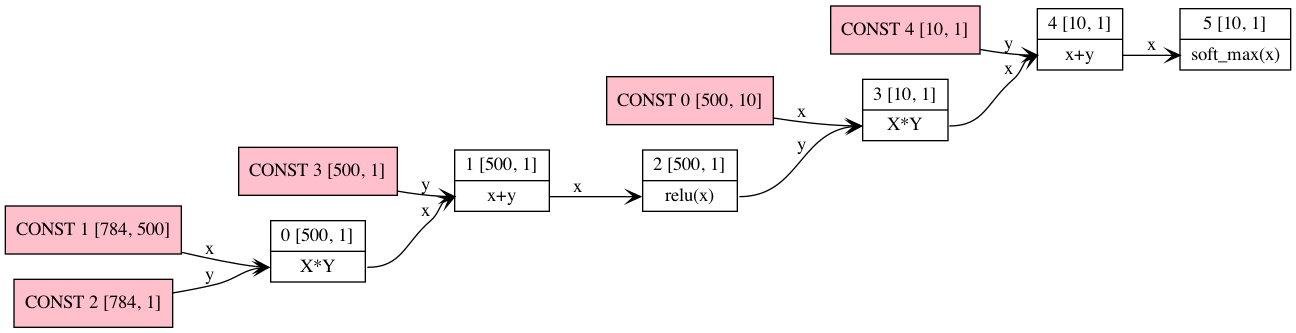
-
+``` bash
+$ ../../build/bin/mnist-train mnist-cnn mnist-cnn-f32.gguf data/MNIST/raw/train-images-idx3-ubyte data/MNIST/raw/train-labels-idx1-ubyte
+```
+As always, the evaluation is done using `mnist-eval` and like with the fully connected network the GGML graph is exported to `mnist-cnn-f32.ggml`.
## Web demo
-The example can be compiled with Emscripten like this:
+The evaluation code can be compiled to WebAssembly using [Emscripten](https://emscripten.org/) (may need to re-login to update `$PATH` after installation).
+First, copy the GGUF file of either of the trained models to `examples/mnist` and name it `mnist-f32.gguf`.
+Copy the test set to `examples/mnist` and name it `t10k-images-idx3-ubyte`.
+Symlinking these files will *not* work!
+Compile the code like so:
```bash
-cd examples/mnist
-emcc -I../../include -I../../include/ggml -I../../examples ../../src/ggml.c ../../src/ggml-quants.c main.cpp -o web/mnist.js -s EXPORTED_FUNCTIONS='["_wasm_eval","_wasm_random_digit","_malloc","_free"]' -s EXPORTED_RUNTIME_METHODS='["ccall"]' -s ALLOW_MEMORY_GROWTH=1 --preload-file models/mnist
+$ emcc -I../../include -I../../include/ggml -I../../examples ../../src/ggml.c ../../src/ggml-quants.c ../../src/ggml-aarch64.c mnist-common.cpp -o web/mnist.js -s EXPORTED_FUNCTIONS='["_wasm_eval","_wasm_random_digit","_malloc","_free"]' -s EXPORTED_RUNTIME_METHODS='["ccall"]' -s ALLOW_MEMORY_GROWTH=1 --preload-file mnist-f32.gguf --preload-file t10k-images-idx3-ubyte
+```
+
+The compilation output is in `examples/mnist/web`.
+To run it, you need an HTTP server.
+For example:
+
+``` bash
+$ cd web
+$ python3 -m http.server
+
+Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
```
-Online demo: https://mnist.ggerganov.com
+The web demo can then be accessed via the link printed on the console.
+Simply draw a digit on the canvas and the model will try to predict what it's supposed to be.
+Alternatively, click the "Random" button to retrieve a random digit from the test set.
+Be aware that like all neural networks the one we trained is susceptible to distributional shift:
+if the numbers you draw look different than the ones in the training set
+(e.g. because they're not centered) the model will perform comparatively worse.
+An online demo can be accessed [here](https://mnist.ggerganov.com).
+++ /dev/null
-# Convert MNIS h5 transformer model to ggml format
-#
-# Load the (state_dict) saved model using PyTorch
-# Iterate over all variables and write them to a binary file.
-#
-# For each variable, write the following:
-# - Number of dimensions (int)
-# - Name length (int)
-# - Dimensions (int[n_dims])
-# - Name (char[name_length])
-# - Data (float[n_dims])
-#
-# At the start of the ggml file we write the model parameters
-
-import sys
-import struct
-import json
-import numpy as np
-import re
-
-import torch
-import torch.nn as nn
-import torchvision.datasets as dsets
-import torchvision.transforms as transforms
-from torch.autograd import Variable
-
-if len(sys.argv) != 2:
- print("Usage: convert-h5-to-ggml.py model\n")
- sys.exit(1)
-
-state_dict_file = sys.argv[1]
-fname_out = "models/mnist/ggml-model-f32.bin"
-
-state_dict = torch.load(state_dict_file, map_location=torch.device('cpu'))
-#print (model)
-
-list_vars = state_dict
-print (list_vars)
-
-fout = open(fname_out, "wb")
-
-fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex
-
-
-for name in list_vars.keys():
- data = list_vars[name].squeeze().numpy()
- print("Processing variable: " + name + " with shape: ", data.shape)
- n_dims = len(data.shape);
-
- fout.write(struct.pack("i", n_dims))
-
- data = data.astype(np.float32)
- for i in range(n_dims):
- fout.write(struct.pack("i", data.shape[n_dims - 1 - i]))
-
- # data
- data.tofile(fout)
-
-fout.close()
-
-print("Done. Output file: " + fname_out)
-print("")
+++ /dev/null
-#include "ggml.h"
-
-#include "common.h"
-
-#include <cmath>
-#include <cstdio>
-#include <cstring>
-#include <ctime>
-#include <fstream>
-#include <string>
-#include <vector>
-#include <algorithm>
-
-#if defined(_MSC_VER)
-#pragma warning(disable: 4244 4267) // possible loss of data
-#endif
-
-struct mnist_model {
- struct ggml_tensor * conv2d_1_kernel;
- struct ggml_tensor * conv2d_1_bias;
- struct ggml_tensor * conv2d_2_kernel;
- struct ggml_tensor * conv2d_2_bias;
- struct ggml_tensor * dense_weight;
- struct ggml_tensor * dense_bias;
- struct ggml_context * ctx;
-};
-
-bool mnist_model_load(const std::string & fname, mnist_model & model) {
- struct gguf_init_params params = {
- /*.no_alloc =*/ false,
- /*.ctx =*/ &model.ctx,
- };
- gguf_context * ctx = gguf_init_from_file(fname.c_str(), params);
- if (!ctx) {
- fprintf(stderr, "%s: gguf_init_from_file() failed\n", __func__);
- return false;
- }
- model.conv2d_1_kernel = ggml_get_tensor(model.ctx, "kernel1");
- model.conv2d_1_bias = ggml_get_tensor(model.ctx, "bias1");
- model.conv2d_2_kernel = ggml_get_tensor(model.ctx, "kernel2");
- model.conv2d_2_bias = ggml_get_tensor(model.ctx, "bias2");
- model.dense_weight = ggml_get_tensor(model.ctx, "dense_w");
- model.dense_bias = ggml_get_tensor(model.ctx, "dense_b");
- return true;
-}
-
-int mnist_eval(
- const mnist_model & model,
- const int n_threads,
- std::vector<float> digit,
- const char * fname_cgraph
- )
-{
- static size_t buf_size = 100000 * sizeof(float) * 4;
- static void * buf = malloc(buf_size);
-
- struct ggml_init_params params = {
- /*.mem_size =*/ buf_size,
- /*.mem_buffer =*/ buf,
- /*.no_alloc =*/ false,
- };
-
- struct ggml_context * ctx0 = ggml_init(params);
- struct ggml_cgraph * gf = ggml_new_graph(ctx0);
-
- struct ggml_tensor * input = ggml_new_tensor_4d(ctx0, GGML_TYPE_F32, 28, 28, 1, 1);
- memcpy(input->data, digit.data(), ggml_nbytes(input));
- ggml_set_name(input, "input");
- ggml_tensor * cur = ggml_conv_2d(ctx0, model.conv2d_1_kernel, input, 1, 1, 0, 0, 1, 1);
- cur = ggml_add(ctx0, cur, model.conv2d_1_bias);
- cur = ggml_relu(ctx0, cur);
- // Output shape after Conv2D: (26 26 32 1)
- cur = ggml_pool_2d(ctx0, cur, GGML_OP_POOL_MAX, 2, 2, 2, 2, 0, 0);
- // Output shape after MaxPooling2D: (13 13 32 1)
- cur = ggml_conv_2d(ctx0, model.conv2d_2_kernel, cur, 1, 1, 0, 0, 1, 1);
- cur = ggml_add(ctx0, cur, model.conv2d_2_bias);
- cur = ggml_relu(ctx0, cur);
- // Output shape after Conv2D: (11 11 64 1)
- cur = ggml_pool_2d(ctx0, cur, GGML_OP_POOL_MAX, 2, 2, 2, 2, 0, 0);
- // Output shape after MaxPooling2D: (5 5 64 1)
- cur = ggml_cont(ctx0, ggml_permute(ctx0, cur, 1, 2, 0, 3));
- // Output shape after permute: (64 5 5 1)
- cur = ggml_reshape_2d(ctx0, cur, 1600, 1);
- // Final Dense layer
- cur = ggml_add(ctx0, ggml_mul_mat(ctx0, model.dense_weight, cur), model.dense_bias);
- ggml_tensor * probs = ggml_soft_max(ctx0, cur);
- ggml_set_name(probs, "probs");
-
- ggml_build_forward_expand(gf, probs);
- ggml_graph_compute_with_ctx(ctx0, gf, n_threads);
-
- //ggml_graph_print(&gf);
- ggml_graph_dump_dot(gf, NULL, "mnist-cnn.dot");
-
- if (fname_cgraph) {
- // export the compute graph for later use
- // see the "mnist-cpu" example
- ggml_graph_export(gf, fname_cgraph);
-
- fprintf(stderr, "%s: exported compute graph to '%s'\n", __func__, fname_cgraph);
- }
-
- const float * probs_data = ggml_get_data_f32(probs);
- const int prediction = std::max_element(probs_data, probs_data + 10) - probs_data;
- ggml_free(ctx0);
- return prediction;
-}
-
-int main(int argc, char ** argv) {
- srand(time(NULL));
- ggml_time_init();
-
- if (argc != 3) {
- fprintf(stderr, "Usage: %s models/mnist/mnist-cnn.gguf models/mnist/t10k-images.idx3-ubyte\n", argv[0]);
- exit(0);
- }
-
- uint8_t buf[784];
- mnist_model model;
- std::vector<float> digit;
-
- // load the model
- {
- const int64_t t_start_us = ggml_time_us();
-
- if (!mnist_model_load(argv[1], model)) {
- fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, argv[1]);
- return 1;
- }
-
- const int64_t t_load_us = ggml_time_us() - t_start_us;
-
- fprintf(stdout, "%s: loaded model in %8.2f ms\n", __func__, t_load_us / 1000.0f);
- }
-
- // read a random digit from the test set
- {
- std::ifstream fin(argv[2], std::ios::binary);
- if (!fin) {
- fprintf(stderr, "%s: failed to open '%s'\n", __func__, argv[2]);
- return 1;
- }
-
- // seek to a random digit: 16-byte header + 28*28 * (random 0 - 10000)
- fin.seekg(16 + 784 * (rand() % 10000));
- fin.read((char *) &buf, sizeof(buf));
- }
-
- // render the digit in ASCII
- {
- digit.resize(sizeof(buf));
-
- for (int row = 0; row < 28; row++) {
- for (int col = 0; col < 28; col++) {
- fprintf(stderr, "%c ", (float)buf[row*28 + col] > 230 ? '*' : '_');
- digit[row*28 + col] = ((float)buf[row*28 + col] / 255.0f);
- }
-
- fprintf(stderr, "\n");
- }
-
- fprintf(stderr, "\n");
- }
-
- const int prediction = mnist_eval(model, 1, digit, nullptr);
- fprintf(stdout, "%s: predicted digit is %d\n", __func__, prediction);
- ggml_free(model.ctx);
- return 0;
-}
+++ /dev/null
-// Use a pre-generated MNIST compute graph for inference on the CPU
-//
-// You can generate a compute graph using the "mnist" tool:
-//
-// $ ./bin/mnist ./models/mnist/ggml-model-f32.bin ../examples/mnist/models/mnist/t10k-images.idx3-ubyte
-//
-// This command creates the "mnist.ggml" file, which contains the generated compute graph.
-// Now, you can re-use the compute graph with the "mnist-cpu" tool:
-//
-// $ ./bin/mnist-cpu ./models/mnist/mnist.ggml ../examples/mnist/models/mnist/t10k-images.idx3-ubyte
-//
-
-#include "ggml.h"
-
-#include <algorithm>
-#include <cmath>
-#include <cstdio>
-#include <cstring>
-#include <ctime>
-#include <fstream>
-#include <vector>
-
-#if defined(_MSC_VER)
-#pragma warning(disable: 4244 4267) // possible loss of data
-#endif
-
-// evaluate the MNIST compute graph
-//
-// - fname_cgraph: path to the compute graph
-// - n_threads: number of threads to use
-// - digit: 784 pixel values
-//
-// returns 0 - 9 prediction
-int mnist_eval(
- const char * fname_cgraph,
- const int n_threads,
- std::vector<float> digit) {
- // load the compute graph
- struct ggml_context * ctx_data = NULL;
- struct ggml_context * ctx_eval = NULL;
-
- struct ggml_cgraph * gfi = ggml_graph_import(fname_cgraph, &ctx_data, &ctx_eval);
-
- // param export/import test
- GGML_ASSERT(ggml_graph_get_tensor(gfi, "fc1_bias")->op_params[0] == int(0xdeadbeef));
-
- // allocate work context
- // needed during ggml_graph_compute() to allocate a work tensor
- static size_t buf_size = 128ull*1024*1024; // TODO
- static void * buf = malloc(buf_size);
-
- struct ggml_init_params params = {
- /*.mem_size =*/ buf_size,
- /*.mem_buffer =*/ buf,
- /*.no_alloc =*/ false,
- };
-
- struct ggml_context * ctx_work = ggml_init(params);
-
- struct ggml_tensor * input = ggml_graph_get_tensor(gfi, "input");
- memcpy(input->data, digit.data(), ggml_nbytes(input));
-
- ggml_graph_compute_with_ctx(ctx_work, gfi, n_threads);
-
- const float * probs_data = ggml_get_data_f32(ggml_graph_get_tensor(gfi, "probs"));
-
- const int prediction = std::max_element(probs_data, probs_data + 10) - probs_data;
-
- ggml_free(ctx_work);
- ggml_free(ctx_data);
- ggml_free(ctx_eval);
-
- return prediction;
-}
-
-int main(int argc, char ** argv) {
- srand(time(NULL));
- ggml_time_init();
-
- if (argc != 3) {
- fprintf(stderr, "Usage: %s models/mnist/mnist.ggml models/mnist/t10k-images.idx3-ubyte\n", argv[0]);
- exit(0);
- }
-
- uint8_t buf[784];
- std::vector<float> digit;
-
- // read a random digit from the test set
- {
- std::ifstream fin(argv[2], std::ios::binary);
- if (!fin) {
- fprintf(stderr, "%s: failed to open '%s'\n", __func__, argv[2]);
- return 1;
- }
-
- // seek to a random digit: 16-byte header + 28*28 * (random 0 - 10000)
- fin.seekg(16 + 784 * (rand() % 10000));
- fin.read((char *) &buf, sizeof(buf));
- }
-
- // render the digit in ASCII
- {
- digit.resize(sizeof(buf));
-
- for (int row = 0; row < 28; row++) {
- for (int col = 0; col < 28; col++) {
- fprintf(stderr, "%c ", (float)buf[row*28 + col] > 230 ? '*' : '_');
- digit[row*28 + col] = ((float)buf[row*28 + col]);
- }
-
- fprintf(stderr, "\n");
- }
-
- fprintf(stderr, "\n");
- }
-
- const int prediction = mnist_eval(argv[1], 1, digit);
-
- fprintf(stdout, "%s: predicted digit is %d\n", __func__, prediction);
-
- return 0;
-}
+++ /dev/null
-// Use a pre-generated MNIST compute graph for inference on the M1 GPU via MPS
-//
-// You can generate a compute graph using the "mnist" tool:
-//
-// $ ./bin/mnist ./models/mnist/ggml-model-f32.bin ../examples/mnist/models/mnist/t10k-images.idx3-ubyte
-//
-// This command creates the "mnist.ggml" file, which contains the generated compute graph.
-// Now, you can re-use the compute graph on the GPU with the "mnist-mtl" tool:
-//
-// $ ./bin/mnist-mtl ./models/mnist/mnist.ggml ../examples/mnist/models/mnist/t10k-images.idx3-ubyte
-//
-
-#include "ggml.h"
-
-#include "main-mtl.h"
-
-#include <cmath>
-#include <cstdio>
-#include <cstring>
-#include <ctime>
-#include <fstream>
-#include <vector>
-
-// evaluate the MNIST compute graph
-//
-// - fname_cgraph: path to the compute graph
-// - digit: 784 pixel values
-//
-// returns 0 - 9 prediction
-int mnist_eval(
- const char * fname_cgraph,
- std::vector<float> digit
- ) {
- // load the compute graph
- struct ggml_context * ctx_data = NULL;
- struct ggml_context * ctx_eval = NULL;
-
- struct ggml_cgraph * gf = ggml_graph_import(fname_cgraph, &ctx_data, &ctx_eval);
-
- // allocate work context
- static size_t buf_size = 128ull*1024*1024; // TODO
- static void * buf = malloc(buf_size);
-
- struct ggml_init_params params = {
- /*.mem_size =*/ buf_size,
- /*.mem_buffer =*/ buf,
- /*.no_alloc =*/ false,
- };
-
- struct ggml_context * ctx_work = ggml_init(params);
-
- // this allocates all Metal resources and memory buffers
- auto ctx_mtl = mnist_mtl_init(ctx_data, ctx_eval, ctx_work, gf);
-
- int prediction = -1;
-
- for (int i = 0; i < 1; ++i) {
- struct ggml_tensor * input = ggml_graph_get_tensor(gf, "input");
-
- if (i % 2 == 0) {
- memcpy(input->data, digit.data(), ggml_nbytes(input));
- } else {
- memset(input->data, 0, ggml_nbytes(input));
- }
-
- // the actual inference happens here
- prediction = mnist_mtl_eval(ctx_mtl, gf);
- }
-
- mnist_mtl_free(ctx_mtl);
-
- ggml_free(ctx_work);
- ggml_free(ctx_data);
- ggml_free(ctx_eval);
-
- return prediction;
-}
-
-int main(int argc, char ** argv) {
- srand(time(NULL));
- ggml_time_init();
-
- if (argc != 3) {
- fprintf(stderr, "Usage: %s models/mnist/mnist.ggml models/mnist/t10k-images.idx3-ubyte\n", argv[0]);
- exit(0);
- }
-
- uint8_t buf[784];
- std::vector<float> digit;
-
- // read a random digit from the test set
- {
- std::ifstream fin(argv[2], std::ios::binary);
- if (!fin) {
- fprintf(stderr, "%s: failed to open '%s'\n", __func__, argv[2]);
- return 1;
- }
-
- // seek to a random digit: 16-byte header + 28*28 * (random 0 - 10000)
- fin.seekg(16 + 784 * (rand() % 10000));
- fin.read((char *) &buf, sizeof(buf));
- }
-
- // render the digit in ASCII
- {
- digit.resize(sizeof(buf));
-
- for (int row = 0; row < 28; row++) {
- for (int col = 0; col < 28; col++) {
- fprintf(stderr, "%c ", (float)buf[row*28 + col] > 230 ? '*' : '_');
- digit[row*28 + col] = ((float)buf[row*28 + col]);
- }
-
- fprintf(stderr, "\n");
- }
-
- fprintf(stderr, "\n");
- }
-
- const int prediction = mnist_eval(argv[1], digit);
-
- fprintf(stdout, "%s: predicted digit is %d\n", __func__, prediction);
-
- return 0;
-}
+++ /dev/null
-#pragma once
-
-struct ggml_context;
-struct ggml_cgraph;
-
-#ifdef __cplusplus
-extern "C" {
-#endif
-
-struct ggml_mtl_context;
-
-struct ggml_mtl_context * mnist_mtl_init(
- struct ggml_context * ctx_data,
- struct ggml_context * ctx_eval,
- struct ggml_context * ctx_work,
- struct ggml_cgraph * gf);
-
-void mnist_mtl_free(struct ggml_mtl_context * ctx);
-
-int mnist_mtl_eval(
- struct ggml_mtl_context * ctx,
- struct ggml_cgraph * gf);
-
-#ifdef __cplusplus
-}
-#endif
+++ /dev/null
-#import "main-mtl.h"
-
-#import "ggml.h"
-
-#import <Foundation/Foundation.h>
-#import <Metal/Metal.h>
-#import <MetalPerformanceShaders/MetalPerformanceShaders.h>
-
-// TODO: couldn't get this to work
-//#define GGML_MTL_HEAP
-
-struct ggml_mtl_context {
- struct ggml_context * ctx_data;
- struct ggml_context * ctx_eval;
- struct ggml_context * ctx_work;
-
- id<MTLDevice> device;
- id<MTLCommandQueue> queue;
- id<MTLLibrary> library;
-
-#ifdef GGML_MTL_HEAP
- id<MTLHeap> heap_data;
- id<MTLHeap> heap_eval;
-#else
- id<MTLBuffer> buffer_data;
- id<MTLBuffer> buffer_eval;
-#endif
-
- id<MTLBuffer> out;
-
- // custom kernels
- id<MTLFunction> function_add;
- id<MTLComputePipelineState> pipeline_add;
-
- id<MTLFunction> function_relu;
- id<MTLComputePipelineState> pipeline_relu;
-
- id<MTLFunction> function_soft_max;
- id<MTLComputePipelineState> pipeline_soft_max;
-};
-
-// MSL code
-NSString * const msl_library_mnist = @"\
-#include <metal_stdlib> \n\
-using namespace metal; \n\
- \n\
-#define MAX(x, y) ((x) > (y) ? (x) : (y)) \n\
- \n\
-constant int k_digits [[function_constant(0)]]; \n\
- \n\
-kernel void kernel_add( \n\
- device const float * src0, \n\
- device const float * src1, \n\
- device float * dst, \n\
- uint gid[[thread_position_in_grid]]) { \n\
- dst[gid] = src0[gid] + src1[gid]; \n\
-} \n\
- \n\
-kernel void kernel_relu( \n\
- device const float * src, \n\
- device float * dst, \n\
- uint gid[[thread_position_in_grid]]) { \n\
- dst[gid] = max(0.0f, src[gid]); \n\
-} \n\
- \n\
-kernel void kernel_soft_max( \n\
- device const float * src, \n\
- device float * dst, \n\
- uint gid[[thread_position_in_grid]]) { \n\
- float max = 0.0f; \n\
- for (int i = 0; i < k_digits; i++) { \n\
- max = MAX(max, src[i]); \n\
- } \n\
- float sum = 0.0f; \n\
- for (int i = 0; i < k_digits; i++) { \n\
- dst[i] = exp(src[i] - max); \n\
- sum += dst[i]; \n\
- } \n\
- for (int i = 0; i < k_digits; i++) { \n\
- dst[i] /= sum; \n\
- } \n\
-} \n\
-";
-
-struct ggml_mtl_context * mnist_mtl_init(
- struct ggml_context * ctx_data,
- struct ggml_context * ctx_eval,
- struct ggml_context * ctx_work,
- struct ggml_cgraph * gf) {
- fprintf(stderr, "%s: allocating\n", __func__);
-
- struct ggml_mtl_context * ctx = malloc(sizeof(struct ggml_mtl_context));
-
- ctx->ctx_data = ctx_data;
- ctx->ctx_eval = ctx_eval;
- ctx->ctx_work = ctx_work;
-
- ctx->device = MTLCreateSystemDefaultDevice();
- ctx->queue = [ctx->device newCommandQueue];
-
- // determine if we can use MPS
- if (MPSSupportsMTLDevice(ctx->device)) {
- fprintf(stderr, "%s: using MPS\n", __func__);
- } else {
- fprintf(stderr, "%s: not using MPS\n", __func__);
- GGML_ASSERT(false && "MPS not supported");
- }
-
- // compile from source string and show compile log
- {
- NSError * error = nil;
- ctx->library = [ctx->device newLibraryWithSource:msl_library_mnist options:nil error:&error];
- if (error) {
- fprintf(stderr, "%s: error: %s\n", __func__, [[error description] UTF8String]);
- exit(1);
- }
- }
-
- // load kernels
- {
- const int k_digits = ggml_graph_get_tensor(gf, "probs")->ne[0];
-
- MTLFunctionConstantValues * constants = [MTLFunctionConstantValues new];
- [constants setConstantValue:&k_digits type:MTLDataTypeInt withName:@"k_digits"];
-
- ctx->function_add = [ctx->library newFunctionWithName:@"kernel_add"];
- ctx->pipeline_add = [ctx->device newComputePipelineStateWithFunction:ctx->function_add error:nil];
- fprintf(stderr, "%s: loaded kernel_add: %p\n", __func__, (void *) ctx->pipeline_add);
-
- ctx->function_relu = [ctx->library newFunctionWithName:@"kernel_relu"];
- ctx->pipeline_relu = [ctx->device newComputePipelineStateWithFunction:ctx->function_relu error:nil];
- fprintf(stderr, "%s: loaded kernel_relu: %p\n", __func__, (void *) ctx->pipeline_relu);
-
- ctx->function_soft_max = [ctx->library newFunctionWithName:@"kernel_soft_max" constantValues:constants error:nil];
- ctx->pipeline_soft_max = [ctx->device newComputePipelineStateWithFunction:ctx->function_soft_max error:nil];
- fprintf(stderr, "%s: loaded kernel_soft_max: %p\n", __func__, (void *) ctx->pipeline_soft_max);
- }
-
-#ifdef GGML_MTL_HEAP
- // MTLHeap approach
-
- // pin ctx_data memory to GPU
- // use MTLStorageModeShared to allow us to initialize the weights from the CPU
- // TODO: how to use MTLStorageModeManaged?
- // TODO: see if we can avoid this copy somehow
- {
- const void * mem_buffer = ggml_get_mem_buffer(ctx_data);
- const size_t mem_size = ggml_get_mem_size(ctx_data);
-
- MTLHeapDescriptor * heap_desc = [MTLHeapDescriptor new];
- heap_desc.storageMode = MTLStorageModeShared;
- heap_desc.size = mem_size;
-
- printf("heap_desc.size = %zu\n", mem_size);
-
- ctx->heap_data = [ctx->device newHeapWithDescriptor:heap_desc];
- [ctx->heap_data setPurgeableState:MTLPurgeableStateNonVolatile]; // TODO: is this needed?
- ctx->heap_data.label = @"heap_data";
-
- printf("ctx->heap_data.size = %zu\n", [ctx->heap_data size]);
-
- id<MTLBuffer> buffer = [ctx->heap_data newBufferWithLength:mem_size options:MTLResourceStorageModeShared];
- if (!buffer) {
- fprintf(stderr, "%s: error: failed to allocate buffer\n", __func__);
- exit(1);
- }
-
- // copy data from CPU to GPU
- memcpy([buffer contents], mem_buffer, mem_size);
-
- fprintf(stderr, "%s: allocated data heap, size = %zu\n", __func__, mem_size);
- }
-
- // pin ctx_eval memory to GPU
- // this heap will be used for the intermediate results of the evaluation
- {
- const size_t mem_size = ggml_get_mem_size(ctx_eval);
-
- MTLHeapDescriptor * heap_desc = [MTLHeapDescriptor new];
- heap_desc.storageMode = MTLStorageModePrivate; // GPU only
- heap_desc.size = mem_size;
-
- ctx->heap_eval = [ctx->device newHeapWithDescriptor:heap_desc];
- [ctx->heap_eval setPurgeableState:MTLPurgeableStateNonVolatile]; // TODO: is this needed?
-
- fprintf(stderr, "%s: allocated eval heap, size = %zu\n", __func__, mem_size);
- }
-#else
- // MTLBuffer approach
-
- // pin ctx_data memory to GPU
- // use MTLStorageModeShared to allow us to initialize the weights from the CPU
- // TODO: how to use MTLStorageModeManaged?
- // TODO: see if we can avoid this copy somehow
- {
- const void * mem_buffer = ggml_get_mem_buffer(ctx_data);
- const size_t mem_size = ggml_get_mem_size(ctx_data);
-
- ctx->buffer_data = [ctx->device newBufferWithBytes:mem_buffer length:mem_size options:MTLResourceStorageModeShared];
-
- fprintf(stderr, "%s: allocated data buffer, size = %zu\n", __func__, mem_size);
- }
-
- // pin ctx_eval memory to GPU
- // this buffer will be used for the intermediate results of the evaluation
- {
- const size_t mem_size = ggml_get_mem_size(ctx_eval);
-
- ctx->buffer_eval = [ctx->device newBufferWithLength:mem_size options:MTLResourceStorageModePrivate];
-
- fprintf(stderr, "%s: allocated eval buffer, size = %zu\n", __func__, mem_size);
- }
-#endif
-
- // allocate buffer for result extraction
- {
- const size_t mem_size = ggml_nbytes(gf->nodes[gf->n_nodes - 1]);
-
- ctx->out = [ctx->device newBufferWithLength:mem_size options:MTLResourceStorageModeShared];
-
- fprintf(stderr, "%s: allocated out buffer, size = %zu\n", __func__, mem_size);
- }
-
- return ctx;
-}
-
-void mnist_mtl_free(struct ggml_mtl_context * ctx) {
- fprintf(stderr, "%s: deallocating\n", __func__);
-
- free(ctx);
-}
-
-#ifdef GGML_MTL_HEAP
-
-// make a view of the respective MTL heap
-id<MTLBuffer> mnist_mtl_get_buffer_on_heap(struct ggml_mtl_context * ctx, struct ggml_tensor * t) {
- const int64_t offs_data = (int64_t) t->data - (int64_t) ggml_get_mem_buffer(ctx->ctx_data);
- const int64_t offs_eval = (int64_t) t->data - (int64_t) ggml_get_mem_buffer(ctx->ctx_eval);
-
- const bool is_data = (offs_eval < 0) || (offs_data >= 0 && offs_data < offs_eval);
-
- const size_t t_size = ggml_nbytes(t);
- const size_t t_offs = is_data ? offs_data : offs_eval;
-
- id<MTLBuffer> result;
-
- if (is_data) {
- fprintf(stderr, "%s: data tensor '%16s', offs = %8ld, size = %8ld\n", __func__, t->name, t_offs, t_size);
- result = [ctx->heap_data newBufferWithLength:t_size options:MTLResourceStorageModeShared offset:t_offs];
- } else {
- fprintf(stderr, "%s: eval tensor '%16s', offs = %8ld, size = %8ld\n", __func__, t->name, t_offs, t_size);
- result = [ctx->heap_eval newBufferWithLength:t_size options:MTLResourceStorageModePrivate offset:t_offs];
- }
-
- if (result == nil) {
- fprintf(stderr, "%s: error: buffer is nil\n", __func__);
- GGML_ASSERT(false);
- }
-
- return result;
-}
-
-#else
-
-// get data / eval buffer + offset
-id<MTLBuffer> mnist_mtl_get_buffer(struct ggml_mtl_context * ctx, struct ggml_tensor * t, size_t * offs) {
- const int64_t offs_data = (int64_t) t->data - (int64_t) ggml_get_mem_buffer(ctx->ctx_data);
- const int64_t offs_eval = (int64_t) t->data - (int64_t) ggml_get_mem_buffer(ctx->ctx_eval);
-
- const bool is_data = (offs_eval < 0) || (offs_data >= 0 && offs_data < offs_eval);
-
- const size_t t_size = ggml_nbytes(t);
- const size_t t_offs = is_data ? offs_data : offs_eval;
-
- id<MTLBuffer> result;
-
- if (is_data) {
- fprintf(stderr, "%s: data tensor '%16s', offs = %8ld, size = %8ld\n", __func__, t->name, t_offs, t_size);
- result = ctx->buffer_data;
- } else {
- fprintf(stderr, "%s: eval tensor '%16s', offs = %8ld, size = %8ld\n", __func__, t->name, t_offs, t_size);
- result = ctx->buffer_eval;
- }
-
- if (result == nil) {
- fprintf(stderr, "%s: error: buffer is nil\n", __func__);
- GGML_ASSERT(false);
- }
-
- if (offs != nil) {
- *offs = t_offs;
- }
-
- return result;
-}
-
-#endif
-
-int mnist_mtl_eval(
- struct ggml_mtl_context * ctx,
- struct ggml_cgraph * gf) {
- fprintf(stderr, "%s: evaluating\n", __func__);
-
- id<MTLCommandBuffer> command_buffer = [ctx->queue commandBuffer];
- id<MTLComputeCommandEncoder> encoder = nil;
-
- size_t offs_src0;
- size_t offs_src1;
- size_t offs_dst;
-
- // copy the input data to the GPU
- {
- struct ggml_tensor * inp = ggml_graph_get_tensor(gf, "input");
-
- id<MTLBuffer> id_dst = mnist_mtl_get_buffer(ctx, inp, &offs_src0);
-
- memcpy((char *) id_dst.contents + offs_src0, inp->data, ggml_nbytes(inp));
- }
-
- for (int i = 0; i < gf->n_nodes; ++i) {
- fprintf(stderr, "%s: encoding node %3d, op = %8s\n", __func__, i, ggml_op_name(gf->nodes[i]->op));
-
- switch (gf->nodes[i]->op) {
- case GGML_OP_ADD:
- {
- if (encoder == nil) {
- encoder = [command_buffer computeCommandEncoder];
- }
-
- id<MTLBuffer> id_src0 = mnist_mtl_get_buffer(ctx, gf->nodes[i]->src[0], &offs_src0);
- id<MTLBuffer> id_src1 = mnist_mtl_get_buffer(ctx, gf->nodes[i]->src[1], &offs_src1);
- id<MTLBuffer> id_dst = mnist_mtl_get_buffer(ctx, gf->nodes[i], &offs_dst);
-
- [encoder setComputePipelineState:ctx->pipeline_add];
- [encoder setBuffer:id_src0 offset:offs_src0 atIndex:0];
- [encoder setBuffer:id_src1 offset:offs_src1 atIndex:1];
- [encoder setBuffer:id_dst offset:offs_dst atIndex:2];
-
- const int64_t n = ggml_nelements(gf->nodes[i]);
-
- [encoder dispatchThreadgroups:MTLSizeMake(n, 1, 1) threadsPerThreadgroup:MTLSizeMake(1, 1, 1)];
- } break;
- case GGML_OP_UNARY:
- switch (ggml_get_unary_op(gf->nodes[i])) {
- case GGML_UNARY_OP_RELU:
- {
- if (encoder == nil) {
- encoder = [command_buffer computeCommandEncoder];
- }
-
- id<MTLBuffer> id_src = mnist_mtl_get_buffer(ctx, gf->nodes[i]->src[0], &offs_src0);
- id<MTLBuffer> id_dst = mnist_mtl_get_buffer(ctx, gf->nodes[i], &offs_dst);
-
- [encoder setComputePipelineState:ctx->pipeline_relu];
- [encoder setBuffer:id_src offset:offs_src0 atIndex:0];
- [encoder setBuffer:id_dst offset:offs_dst atIndex:1];
-
- const int64_t n = ggml_nelements(gf->nodes[i]);
-
- [encoder dispatchThreadgroups:MTLSizeMake(n, 1, 1) threadsPerThreadgroup:MTLSizeMake(1, 1, 1)];
- } break;
- default:
- {
- fprintf(stderr, "%s: node %3d, op = %8s, unary op %d not implemented\n", __func__, i, ggml_op_name(gf->nodes[i]->op), (int) ggml_get_unary_op(gf->nodes[i]));
- GGML_ASSERT(false);
- return -1;
- }
- break;
- } break;
- case GGML_OP_SOFT_MAX:
- {
-#if 0
- // NOTE: MPSMatrixSoftMax is not working properly, probably there is a bug
-
- if (encoder != nil) {
- [encoder endEncoding];
- encoder = nil;
- }
-
- // use MPSMatrixSoftMax
- id<MTLBuffer> id_src = mnist_mtl_get_buffer(ctx, gf->nodes[i]->src0, &offs_src0);
- id<MTLBuffer> id_dst = mnist_mtl_get_buffer(ctx, gf->nodes[i], &offs_dst);
-
- MPSMatrixDescriptor * desc = [MPSMatrixDescriptor
- matrixDescriptorWithRows:1 columns:gf->nodes[i]->ne[0] rowBytes:gf->nodes[i]->nb[1] dataType:MPSDataTypeFloat32];
-
- MPSMatrix * mat_src = [[MPSMatrix alloc] initWithBuffer:id_src offset:offs_src0 descriptor:desc];
- MPSMatrix * mat_dst = [[MPSMatrix alloc] initWithBuffer:id_dst offset:offs_dst descriptor:desc];
-
- MPSMatrixSoftMax * softmax = [[MPSMatrixSoftMax alloc] initWithDevice:ctx->device];
-
- [softmax encodeToCommandBuffer:command_buffer inputMatrix:mat_src resultMatrix:mat_dst];
-#else
- if (encoder == nil) {
- encoder = [command_buffer computeCommandEncoder];
- }
-
- id<MTLBuffer> id_src = mnist_mtl_get_buffer(ctx, gf->nodes[i]->src[0], &offs_src0);
- id<MTLBuffer> id_dst = mnist_mtl_get_buffer(ctx, gf->nodes[i], &offs_dst);
-
- [encoder setComputePipelineState:ctx->pipeline_soft_max];
- [encoder setBuffer:id_src offset:offs_src0 atIndex:0];
- [encoder setBuffer:id_dst offset:offs_dst atIndex:1];
-
- [encoder dispatchThreadgroups:MTLSizeMake(1, 1, 1) threadsPerThreadgroup:MTLSizeMake(1, 1, 1)];
-#endif
- } break;
- case GGML_OP_MUL_MAT:
- {
- if (encoder != nil) {
- [encoder endEncoding];
- encoder = nil;
- }
-
- // use MPSMatrixMultiplication
- id<MTLBuffer> id_src0 = mnist_mtl_get_buffer(ctx, gf->nodes[i]->src[0], &offs_src0);
- id<MTLBuffer> id_src1 = mnist_mtl_get_buffer(ctx, gf->nodes[i]->src[1], &offs_src1);
- id<MTLBuffer> id_dst = mnist_mtl_get_buffer(ctx, gf->nodes[i], &offs_dst);
-
- const int64_t ncols0 = gf->nodes[i]->src[0]->ne[0];
- const int64_t nrows0 = gf->nodes[i]->src[0]->ne[1];
-
- const int64_t ncols1 = gf->nodes[i]->src[1]->ne[0];
- const int64_t nrows1 = gf->nodes[i]->src[1]->ne[1];
-
- const int64_t ncols2 = gf->nodes[i]->ne[0];
- const int64_t nrows2 = gf->nodes[i]->ne[1];
-
- GGML_ASSERT(ncols0 == ncols1);
-
- MPSMatrixDescriptor * desc0 = [MPSMatrixDescriptor
- matrixDescriptorWithRows:nrows0 columns:ncols0 rowBytes:gf->nodes[i]->src[0]->nb[1] dataType:MPSDataTypeFloat32];
- MPSMatrixDescriptor * desc1 = [MPSMatrixDescriptor
- matrixDescriptorWithRows:nrows1 columns:ncols1 rowBytes:gf->nodes[i]->src[1]->nb[1] dataType:MPSDataTypeFloat32];
- MPSMatrixDescriptor * desc2 = [MPSMatrixDescriptor
- matrixDescriptorWithRows:nrows2 columns:ncols2 rowBytes:gf->nodes[i]->nb[1] dataType:MPSDataTypeFloat32];
-
- MPSMatrix * mat_src0 = [[MPSMatrix alloc] initWithBuffer:id_src0 offset:offs_src0 descriptor:desc0];
- MPSMatrix * mat_src1 = [[MPSMatrix alloc] initWithBuffer:id_src1 offset:offs_src1 descriptor:desc1];
- MPSMatrix * mat_dst = [[MPSMatrix alloc] initWithBuffer:id_dst offset:offs_dst descriptor:desc2];
-
- MPSMatrixMultiplication * mul = [[MPSMatrixMultiplication alloc] initWithDevice:ctx->device
- transposeLeft:false transposeRight:true resultRows:nrows1 resultColumns:nrows0 interiorColumns:ncols0 alpha:1.0 beta:0.0];
-
- [mul encodeToCommandBuffer:command_buffer leftMatrix:mat_src1 rightMatrix:mat_src0 resultMatrix:mat_dst];
- } break;
- default:
- {
- fprintf(stderr, "%s: node %3d, op = %8s not implemented\n", __func__, i, ggml_op_name(gf->nodes[i]->op));
- GGML_ASSERT(false);
- return -1;
- }
- }
- }
-
- // extract results from the GPU
- {
- if (encoder != nil) {
- [encoder endEncoding];
- encoder = nil;
- }
-
- struct ggml_tensor * out = gf->nodes[gf->n_nodes - 1];
-
- id<MTLBuffer> id_src = mnist_mtl_get_buffer(ctx, out, &offs_src0);
- id<MTLBuffer> id_dst = ctx->out;
-
- id<MTLBlitCommandEncoder> encoder_blit = [command_buffer blitCommandEncoder];
- [encoder_blit copyFromBuffer:id_src sourceOffset:offs_src0 toBuffer:id_dst destinationOffset:0 size:ggml_nbytes(out)];
- [encoder_blit endEncoding];
- }
-
- [command_buffer commit];
- [command_buffer waitUntilCompleted];
-
- {
- const double time_elapsed = [command_buffer GPUEndTime] - [command_buffer GPUStartTime];
- fprintf(stderr, "%s: time elapsed = %f\n", __func__, time_elapsed);
- }
-
- // select the most probable digit
- int result = -1;
- {
- const float * probs = ctx->out.contents;
-
- float prob = probs[0];
-
- for (int i = 0; i < 10; ++i) {
- fprintf(stderr, "%s: probs[%2d] = %f\n", __func__, i, probs[i]);
-
- if (probs[i] > prob) {
- result = i;
- prob = probs[i];
- }
- }
- }
-
- return result;
-}
+++ /dev/null
-#include "ggml.h"
-
-#include "common.h"
-
-#include <cmath>
-#include <cstdio>
-#include <cstring>
-#include <ctime>
-#include <fstream>
-#include <string>
-#include <vector>
-#include <algorithm>
-
-#if defined(_MSC_VER)
-#pragma warning(disable: 4244 4267) // possible loss of data
-#endif
-
-// default hparams
-struct mnist_hparams {
- int32_t n_input = 784;
- int32_t n_hidden = 500;
- int32_t n_classes = 10;
-};
-
-struct mnist_model {
- mnist_hparams hparams;
-
- struct ggml_tensor * fc1_weight;
- struct ggml_tensor * fc1_bias;
-
- struct ggml_tensor * fc2_weight;
- struct ggml_tensor * fc2_bias;
-
- struct ggml_context * ctx;
-};
-
-// load the model's weights from a file
-bool mnist_model_load(const std::string & fname, mnist_model & model) {
- printf("%s: loading model from '%s'\n", __func__, fname.c_str());
-
- auto fin = std::ifstream(fname, std::ios::binary);
- if (!fin) {
- fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str());
- return false;
- }
-
- // verify magic
- {
- uint32_t magic;
- fin.read((char *) &magic, sizeof(magic));
- if (magic != GGML_FILE_MAGIC) {
- fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str());
- return false;
- }
- }
-
- auto & ctx = model.ctx;
-
- size_t ctx_size = 0;
-
- {
- const auto & hparams = model.hparams;
-
- const int n_input = hparams.n_input;
- const int n_hidden = hparams.n_hidden;
- const int n_classes = hparams.n_classes;
-
- ctx_size += n_input * n_hidden * ggml_type_size(GGML_TYPE_F32); // fc1 weight
- ctx_size += n_hidden * ggml_type_size(GGML_TYPE_F32); // fc1 bias
-
- ctx_size += n_hidden * n_classes * ggml_type_size(GGML_TYPE_F32); // fc2 weight
- ctx_size += n_classes * ggml_type_size(GGML_TYPE_F32); // fc2 bias
-
- printf("%s: ggml ctx size = %6.2f MB\n", __func__, ctx_size/(1024.0*1024.0));
- }
-
- // create the ggml context
- {
- struct ggml_init_params params = {
- /*.mem_size =*/ ctx_size + 1024*1024,
- /*.mem_buffer =*/ NULL,
- /*.no_alloc =*/ false,
- };
-
- model.ctx = ggml_init(params);
- if (!model.ctx) {
- fprintf(stderr, "%s: ggml_init() failed\n", __func__);
- return false;
- }
- }
-
- // Read FC1 layer 1
- {
- // Read dimensions
- int32_t n_dims;
- fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims));
-
- {
- int32_t ne_weight[2] = { 1, 1 };
- for (int i = 0; i < n_dims; ++i) {
- fin.read(reinterpret_cast<char *>(&ne_weight[i]), sizeof(ne_weight[i]));
- }
-
- // FC1 dimensions taken from file, eg. 768x500
- model.hparams.n_input = ne_weight[0];
- model.hparams.n_hidden = ne_weight[1];
-
- model.fc1_weight = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, model.hparams.n_input, model.hparams.n_hidden);
- fin.read(reinterpret_cast<char *>(model.fc1_weight->data), ggml_nbytes(model.fc1_weight));
- ggml_set_name(model.fc1_weight, "fc1_weight");
- }
-
- {
- int32_t ne_bias[2] = { 1, 1 };
- for (int i = 0; i < n_dims; ++i) {
- fin.read(reinterpret_cast<char *>(&ne_bias[i]), sizeof(ne_bias[i]));
- }
-
- model.fc1_bias = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, model.hparams.n_hidden);
- fin.read(reinterpret_cast<char *>(model.fc1_bias->data), ggml_nbytes(model.fc1_bias));
- ggml_set_name(model.fc1_bias, "fc1_bias");
-
- // just for testing purposes, set some parameters to non-zero
- model.fc1_bias->op_params[0] = 0xdeadbeef;
- }
- }
-
- // Read FC2 layer 2
- {
- // Read dimensions
- int32_t n_dims;
- fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims));
-
- {
- int32_t ne_weight[2] = { 1, 1 };
- for (int i = 0; i < n_dims; ++i) {
- fin.read(reinterpret_cast<char *>(&ne_weight[i]), sizeof(ne_weight[i]));
- }
-
- // FC1 dimensions taken from file, eg. 10x500
- model.hparams.n_classes = ne_weight[1];
-
- model.fc2_weight = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, model.hparams.n_hidden, model.hparams.n_classes);
- fin.read(reinterpret_cast<char *>(model.fc2_weight->data), ggml_nbytes(model.fc2_weight));
- ggml_set_name(model.fc2_weight, "fc2_weight");
- }
-
- {
- int32_t ne_bias[2] = { 1, 1 };
- for (int i = 0; i < n_dims; ++i) {
- fin.read(reinterpret_cast<char *>(&ne_bias[i]), sizeof(ne_bias[i]));
- }
-
- model.fc2_bias = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, model.hparams.n_classes);
- fin.read(reinterpret_cast<char *>(model.fc2_bias->data), ggml_nbytes(model.fc2_bias));
- ggml_set_name(model.fc2_bias, "fc2_bias");
- }
- }
-
- fin.close();
-
- return true;
-}
-
-// evaluate the model
-//
-// - model: the model
-// - n_threads: number of threads to use
-// - digit: 784 pixel values
-//
-// returns 0 - 9 prediction
-int mnist_eval(
- const mnist_model & model,
- const int n_threads,
- std::vector<float> digit,
- const char * fname_cgraph
- ) {
-
- const auto & hparams = model.hparams;
-
- static size_t buf_size = hparams.n_input * sizeof(float) * 32;
- static void * buf = malloc(buf_size);
-
- struct ggml_init_params params = {
- /*.mem_size =*/ buf_size,
- /*.mem_buffer =*/ buf,
- /*.no_alloc =*/ false,
- };
-
- struct ggml_context * ctx0 = ggml_init(params);
- struct ggml_cgraph * gf = ggml_new_graph(ctx0);
-
- struct ggml_tensor * input = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, hparams.n_input);
- memcpy(input->data, digit.data(), ggml_nbytes(input));
- ggml_set_name(input, "input");
-
- // fc1 MLP = Ax + b
- ggml_tensor * fc1 = ggml_add(ctx0, ggml_mul_mat(ctx0, model.fc1_weight, input), model.fc1_bias);
- ggml_tensor * fc2 = ggml_add(ctx0, ggml_mul_mat(ctx0, model.fc2_weight, ggml_relu(ctx0, fc1)), model.fc2_bias);
-
- // soft max
- ggml_tensor * probs = ggml_soft_max(ctx0, fc2);
- ggml_set_name(probs, "probs");
-
- // build / export / run the computation graph
- ggml_build_forward_expand(gf, probs);
- ggml_graph_compute_with_ctx(ctx0, gf, n_threads);
-
- //ggml_graph_print (&gf);
- ggml_graph_dump_dot(gf, NULL, "mnist.dot");
-
- if (fname_cgraph) {
- // export the compute graph for later use
- // see the "mnist-cpu" example
- ggml_graph_export(gf, "mnist.ggml");
-
- fprintf(stderr, "%s: exported compute graph to '%s'\n", __func__, fname_cgraph);
- }
-
- const float * probs_data = ggml_get_data_f32(probs);
-
- const int prediction = std::max_element(probs_data, probs_data + 10) - probs_data;
-
- ggml_free(ctx0);
-
- return prediction;
-}
-
-#ifdef __cplusplus
-extern "C" {
-#endif
-
-int wasm_eval(uint8_t * digitPtr) {
- mnist_model model;
- if (!mnist_model_load("models/mnist/ggml-model-f32.bin", model)) {
- fprintf(stderr, "error loading model\n");
- return -1;
- }
- std::vector<float> digit(digitPtr, digitPtr + 784);
- int result = mnist_eval(model, 1, digit, nullptr);
- ggml_free(model.ctx);
-
- return result;
-}
-
-int wasm_random_digit(char * digitPtr) {
- auto fin = std::ifstream("models/mnist/t10k-images.idx3-ubyte", std::ios::binary);
- if (!fin) {
- fprintf(stderr, "failed to open digits file\n");
- return 0;
- }
- srand(time(NULL));
-
- // Seek to a random digit: 16-byte header + 28*28 * (random 0 - 10000)
- fin.seekg(16 + 784 * (rand() % 10000));
- fin.read(digitPtr, 784);
-
- return 1;
-}
-
-#ifdef __cplusplus
-}
-#endif
-
-int main(int argc, char ** argv) {
- srand(time(NULL));
- ggml_time_init();
-
- if (argc != 3) {
- fprintf(stderr, "Usage: %s models/mnist/ggml-model-f32.bin models/mnist/t10k-images.idx3-ubyte\n", argv[0]);
- exit(0);
- }
-
- uint8_t buf[784];
- mnist_model model;
- std::vector<float> digit;
-
- // load the model
- {
- const int64_t t_start_us = ggml_time_us();
-
- if (!mnist_model_load(argv[1], model)) {
- fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, "models/ggml-model-f32.bin");
- return 1;
- }
-
- const int64_t t_load_us = ggml_time_us() - t_start_us;
-
- fprintf(stdout, "%s: loaded model in %8.2f ms\n", __func__, t_load_us / 1000.0f);
- }
-
- // read a random digit from the test set
- {
- std::ifstream fin(argv[2], std::ios::binary);
- if (!fin) {
- fprintf(stderr, "%s: failed to open '%s'\n", __func__, argv[2]);
- return 1;
- }
-
- // seek to a random digit: 16-byte header + 28*28 * (random 0 - 10000)
- fin.seekg(16 + 784 * (rand() % 10000));
- fin.read((char *) &buf, sizeof(buf));
- }
-
- // render the digit in ASCII
- {
- digit.resize(sizeof(buf));
-
- for (int row = 0; row < 28; row++) {
- for (int col = 0; col < 28; col++) {
- fprintf(stderr, "%c ", (float)buf[row*28 + col] > 230 ? '*' : '_');
- digit[row*28 + col] = ((float)buf[row*28 + col]);
- }
-
- fprintf(stderr, "\n");
- }
-
- fprintf(stderr, "\n");
- }
-
- const int prediction = mnist_eval(model, 1, digit, "mnist.ggml");
-
- fprintf(stdout, "%s: predicted digit is %d\n", __func__, prediction);
-
- ggml_free(model.ctx);
-
- return 0;
-}
+++ /dev/null
-#!/usr/bin/env python3
-import sys
-import gguf
-import numpy as np
-from tensorflow import keras
-from tensorflow.keras import layers
-
-
-def train(model_name):
- if not model_name.endswith(".keras") and not model_name.endswith(".h5"):
- model_name += ".keras"
-
- # Model / data parameters
- num_classes = 10
- input_shape = (28, 28, 1)
-
- # Load the data and split it between train and test sets
- (x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
-
- # Scale images to the [0, 1] range
- x_train = x_train.astype("float32") / 255
- x_test = x_test.astype("float32") / 255
- # Make sure images have shape (28, 28, 1)
- x_train = np.expand_dims(x_train, -1)
- x_test = np.expand_dims(x_test, -1)
- print("x_train shape:", x_train.shape)
- print(x_train.shape[0], "train samples")
- print(x_test.shape[0], "test samples")
-
- # convert class vectors to binary class matrices
- y_train = keras.utils.to_categorical(y_train, num_classes)
- y_test = keras.utils.to_categorical(y_test, num_classes)
-
- model = keras.Sequential(
- [
- keras.Input(shape=input_shape),
- layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
- layers.MaxPooling2D(pool_size=(2, 2)),
- layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
- layers.MaxPooling2D(pool_size=(2, 2)),
- layers.Flatten(),
- layers.Dropout(0.5),
- layers.Dense(num_classes, activation="softmax"),
- ]
- )
-
- model.summary()
- batch_size = 128
- epochs = 15
- model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
- model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
-
- score = model.evaluate(x_test, y_test, verbose=0)
- print("Test loss:", score[0])
- print("Test accuracy:", score[1])
- model.save(model_name)
- print("Keras model saved to '" + model_name + "'")
-
-
-def convert(model_name):
- if not model_name.endswith(".keras") and not model_name.endswith(".h5"):
- model_name += ".keras"
-
- model = keras.models.load_model(model_name)
- if model_name.endswith(".keras"):
- gguf_model_name = model_name[:-6] + ".gguf"
- elif model_name.endswith(".h5"):
- gguf_model_name = model_name[:-3] + ".gguf"
- else:
- gguf_model_name = model_name + ".gguf"
-
- gguf_writer = gguf.GGUFWriter(gguf_model_name, "mnist-cnn")
-
- kernel1 = model.layers[0].weights[0].numpy()
- kernel1 = np.moveaxis(kernel1, [2,3], [0,1])
- kernel1 = kernel1.astype(np.float16)
- gguf_writer.add_tensor("kernel1", kernel1, raw_shape=(32, 1, 3, 3))
-
- bias1 = model.layers[0].weights[1].numpy()
- bias1 = np.repeat(bias1, 26*26)
- gguf_writer.add_tensor("bias1", bias1, raw_shape=(1, 32, 26, 26))
-
- kernel2 = model.layers[2].weights[0].numpy()
- kernel2 = np.moveaxis(kernel2, [0,1,2,3], [2,3,1,0])
- kernel2 = kernel2.astype(np.float16)
- gguf_writer.add_tensor("kernel2", kernel2, raw_shape=(64, 32, 3, 3))
-
- bias2 = model.layers[2].weights[1].numpy()
- bias2 = np.repeat(bias2, 11*11)
- gguf_writer.add_tensor("bias2", bias2, raw_shape=(1, 64, 11, 11))
-
- dense_w = model.layers[-1].weights[0].numpy()
- dense_w = dense_w.transpose()
- gguf_writer.add_tensor("dense_w", dense_w, raw_shape=(10, 1600))
-
- dense_b = model.layers[-1].weights[1].numpy()
- gguf_writer.add_tensor("dense_b", dense_b)
-
- gguf_writer.write_header_to_file()
- gguf_writer.write_kv_data_to_file()
- gguf_writer.write_tensors_to_file()
- gguf_writer.close()
- print("Model converted and saved to '{}'".format(gguf_model_name))
-
-
-if __name__ == '__main__':
- if len(sys.argv) < 3:
- print("Usage: %s <train|convert> <model_name>".format(sys.argv[0]))
- sys.exit(1)
- if sys.argv[1] == 'train':
- train(sys.argv[2])
- elif sys.argv[1] == 'convert':
- convert(sys.argv[2])
- else:
- print("Usage: %s <train|convert> <model_name>".format(sys.argv[0]))
- sys.exit(1)
--- /dev/null
+#include "ggml.h"
+
+#include "mnist-common.h"
+
+#include <algorithm>
+#include <cmath>
+#include <cstdio>
+#include <cstring>
+#include <cstdint>
+#include <fstream>
+#include <random>
+#include <string>
+#include <utility>
+
+bool mnist_image_load(const std::string & fname, float * buf, const int nex) {
+ auto fin = std::ifstream(fname, std::ios::binary);
+ if (!fin) {
+ fprintf(stderr, "failed to open images file %s\n", fname.c_str());
+ return false;
+ }
+ fin.seekg(16);
+
+ uint8_t image[MNIST_NINPUT];
+
+ for (int iex = 0; iex < nex; ++iex) {
+ fin.read((char *) image, sizeof(image));
+
+ for (int i = 0; i < MNIST_NINPUT; ++i) {
+ buf[iex*MNIST_NINPUT + i] = image[i] / 255.0f; // Normalize to [0, 1]
+ }
+ }
+
+ return true;
+}
+
+void mnist_image_print(FILE * stream, const float * image) {
+ static_assert(MNIST_NINPUT == 28*28, "Unexpected MNIST_NINPUT");
+
+ for (int row = 0; row < 28; row++) {
+ for (int col = 0; col < 28; col++) {
+ const int rgb = roundf(255.0f * image[row*28 + col]);
+#ifdef _WIN32
+ fprintf(stream, "%s", rgb >= 220 ? "##" : "__"); // Represented via text.
+#else
+ fprintf(stream, "\033[48;2;%d;%d;%dm \033[0m", rgb, rgb, rgb); // Represented via colored blocks.
+#endif // _WIN32
+ }
+ fprintf(stream, "\n");
+ }
+}
+
+bool mnist_label_load(const std::string & fname, float * buf, const int nex) {
+ auto fin = std::ifstream(fname, std::ios::binary);
+ if (!fin) {
+ fprintf(stderr, "failed to open labels file %s\n", fname.c_str());
+ return 0;
+ }
+ fin.seekg(8);
+
+ uint8_t label;
+
+ for (int iex = 0; iex < nex; ++iex) {
+ fin.read((char *) &label, sizeof(label));
+
+ for (int i = 0; i < MNIST_NCLASSES; ++i) {
+ buf[iex*MNIST_NCLASSES + i] = i == label ? 1.0f : 0.0f;
+ }
+ }
+
+ return true;
+}
+
+mnist_eval_result mnist_graph_eval(const std::string & fname, const float * images, const float * labels, const int nex, const int nthreads) {
+ fprintf(stderr, "%s: trying to load a ggml graph from %s\n", __func__, fname.c_str());
+ mnist_eval_result result;
+
+ struct ggml_context * ctx_data;
+ struct ggml_context * ctx_eval;
+
+ struct ggml_cgraph * gf;
+ {
+ const int64_t t_start_us = ggml_time_us();
+
+ gf = ggml_graph_import(fname.c_str(), &ctx_data, &ctx_eval);
+
+ const int64_t t_total_us = ggml_time_us() - t_start_us;
+ const double t_total_ms = 1e-3*t_total_us;
+ if (gf) {
+ fprintf(stderr, "%s: graph import took %.2lf ms\n", __func__, t_total_ms);
+ }
+ }
+
+ if (!gf) {
+ fprintf(stderr, "%s: could not load a ggml graph from %s\n", __func__, fname.c_str());
+ return result;
+ }
+ fprintf(stderr, "%s: successfully loaded a ggml graph from %s\n", __func__, fname.c_str());
+
+ const size_t buf_size = 100 * 1024*1024;
+ void * buf_compute = malloc(buf_size);
+
+ struct ggml_init_params params = {
+ /*.mem_size =*/ buf_size,
+ /*.mem_buffer =*/ buf_compute,
+ /*.no_alloc =*/ false,
+ };
+
+ struct ggml_context * ctx_compute = ggml_init(params);
+
+ struct ggml_tensor * images_batch = ggml_graph_get_tensor(gf, "images");
+ GGML_ASSERT(images_batch);
+ GGML_ASSERT(images_batch->ne[0] == MNIST_NINPUT || (images_batch->ne[0] == MNIST_HW && images_batch->ne[1] == MNIST_HW));
+
+ struct ggml_tensor * logits_batch = ggml_graph_get_tensor(gf, "logits");
+ GGML_ASSERT(logits_batch);
+ GGML_ASSERT(logits_batch->ne[0] == MNIST_NCLASSES);
+ GGML_ASSERT(logits_batch->ne[2] == 1);
+ GGML_ASSERT(logits_batch->ne[3] == 1);
+
+ GGML_ASSERT(images_batch->ne[1] == logits_batch->ne[1] || images_batch->ne[3] == logits_batch->ne[1]);
+ const int nbatch = logits_batch->ne[1];
+ GGML_ASSERT(nex % nbatch == 0);
+
+ struct ggml_tensor * loss = ggml_graph_get_tensor(gf, "loss");
+
+ {
+ const int64_t t_start_us = ggml_time_us();
+
+ for (int iex0; iex0 < nex; iex0 += nbatch) {
+ memcpy(images_batch->data, images + iex0*MNIST_NINPUT, ggml_nbytes(images_batch));
+ ggml_graph_compute_with_ctx(ctx_compute, gf, nthreads);
+
+ for (int iexb = 0; iexb < nbatch; ++iexb) {
+ const float * probs_data = ggml_get_data_f32(logits_batch) + iexb*MNIST_NCLASSES;
+
+ result.pred.push_back(std::max_element(probs_data, probs_data + MNIST_NCLASSES) - probs_data);
+ }
+
+ result.loss.push_back(*ggml_get_data_f32(loss));
+ }
+
+ const int64_t t_total_us = ggml_time_us() - t_start_us;
+ const double t_total_ms = 1e-3*t_total_us;
+ fprintf(stderr, "%s: model evaluation on %d images took %.2lf ms, %.2lf us/image\n",
+ __func__, nex, t_total_ms, (double) t_total_us/nex);
+ }
+
+ ggml_free(ctx_data);
+ ggml_free(ctx_eval);
+ ggml_free(ctx_compute);
+ free(buf_compute);
+
+ result.success = true;
+ return result;
+}
+
+mnist_model mnist_model_init_from_file(const std::string & fname) {
+ mnist_model model;
+ fprintf(stderr, "%s: loading model weights from '%s'\n", __func__, fname.c_str());
+
+ struct gguf_init_params params = {
+ /*.no_alloc =*/ false,
+ /*.ctx =*/ &model.ctx_weight,
+ };
+ gguf_context * ctx = gguf_init_from_file(fname.c_str(), params);
+ if (!ctx) {
+ fprintf(stderr, "%s: gguf_init_from_file() failed\n", __func__);
+ exit(1);
+ }
+ model.arch = gguf_get_val_str(ctx, gguf_find_key(ctx, "general.architecture"));
+ fprintf(stderr, "%s: model arch is %s\n", __func__, model.arch.c_str());
+
+ if (model.arch == "mnist-fc") {
+ model.fc1_weight = ggml_get_tensor(model.ctx_weight, "fc1.weight");
+ GGML_ASSERT(model.fc1_weight->ne[0] == MNIST_NINPUT);
+ GGML_ASSERT(model.fc1_weight->ne[1] == MNIST_NHIDDEN);
+ GGML_ASSERT(model.fc1_weight->ne[2] == 1);
+ GGML_ASSERT(model.fc1_weight->ne[3] == 1);
+
+ model.fc1_bias = ggml_get_tensor(model.ctx_weight, "fc1.bias");
+ GGML_ASSERT(model.fc1_bias->ne[0] == MNIST_NHIDDEN);
+ GGML_ASSERT(model.fc1_bias->ne[1] == 1);
+ GGML_ASSERT(model.fc1_bias->ne[2] == 1);
+ GGML_ASSERT(model.fc1_bias->ne[3] == 1);
+
+ model.fc2_weight = ggml_get_tensor(model.ctx_weight, "fc2.weight");
+ GGML_ASSERT(model.fc2_weight->ne[0] == MNIST_NHIDDEN);
+ GGML_ASSERT(model.fc2_weight->ne[1] == MNIST_NCLASSES);
+ GGML_ASSERT(model.fc2_weight->ne[2] == 1);
+ GGML_ASSERT(model.fc2_weight->ne[3] == 1);
+
+ model.fc2_bias = ggml_get_tensor(model.ctx_weight, "fc2.bias");
+ GGML_ASSERT(model.fc2_bias->ne[0] == MNIST_NCLASSES);
+ GGML_ASSERT(model.fc2_bias->ne[1] == 1);
+ GGML_ASSERT(model.fc2_bias->ne[2] == 1);
+ GGML_ASSERT(model.fc2_bias->ne[3] == 1);
+ } else if (model.arch == "mnist-cnn") {
+ model.conv1_kernel = ggml_get_tensor(model.ctx_weight, "conv1.kernel");
+ GGML_ASSERT(model.conv1_kernel->type == GGML_TYPE_F32);
+ GGML_ASSERT(model.conv1_kernel->ne[0] == 3);
+ GGML_ASSERT(model.conv1_kernel->ne[1] == 3);
+ GGML_ASSERT(model.conv1_kernel->ne[2] == 1);
+ GGML_ASSERT(model.conv1_kernel->ne[3] == MNIST_CNN_NCB);
+
+ model.conv1_bias = ggml_get_tensor(model.ctx_weight, "conv1.bias");
+ GGML_ASSERT(model.conv1_bias->type == GGML_TYPE_F32);
+ GGML_ASSERT(model.conv1_bias->ne[0] == MNIST_HW);
+ GGML_ASSERT(model.conv1_bias->ne[1] == MNIST_HW);
+ GGML_ASSERT(model.conv1_bias->ne[2] == MNIST_CNN_NCB);
+ GGML_ASSERT(model.conv1_bias->ne[3] == 1);
+
+ model.conv2_kernel = ggml_get_tensor(model.ctx_weight, "conv2.kernel");
+ GGML_ASSERT(model.conv2_kernel->type == GGML_TYPE_F32);
+ GGML_ASSERT(model.conv2_kernel->ne[0] == 3);
+ GGML_ASSERT(model.conv2_kernel->ne[1] == 3);
+ GGML_ASSERT(model.conv2_kernel->ne[2] == MNIST_CNN_NCB);
+ GGML_ASSERT(model.conv2_kernel->ne[3] == MNIST_CNN_NCB*2);
+
+ model.conv2_bias = ggml_get_tensor(model.ctx_weight, "conv2.bias");
+ GGML_ASSERT(model.conv2_bias->type == GGML_TYPE_F32);
+ GGML_ASSERT(model.conv2_bias->ne[0] == MNIST_HW/2);
+ GGML_ASSERT(model.conv2_bias->ne[1] == MNIST_HW/2);
+ GGML_ASSERT(model.conv2_bias->ne[2] == MNIST_CNN_NCB*2);
+ GGML_ASSERT(model.conv2_bias->ne[3] == 1);
+
+ model.dense_weight = ggml_get_tensor(model.ctx_weight, "dense.weight");
+ GGML_ASSERT(model.dense_weight->type == GGML_TYPE_F32);
+ GGML_ASSERT(model.dense_weight->ne[0] == (MNIST_HW/4)*(MNIST_HW/4)*(MNIST_CNN_NCB*2));
+ GGML_ASSERT(model.dense_weight->ne[1] == MNIST_NCLASSES);
+ GGML_ASSERT(model.dense_weight->ne[2] == 1);
+ GGML_ASSERT(model.dense_weight->ne[3] == 1);
+
+ model.dense_bias = ggml_get_tensor(model.ctx_weight, "dense.bias");
+ GGML_ASSERT(model.dense_bias->type == GGML_TYPE_F32);
+ GGML_ASSERT(model.dense_bias->ne[0] == MNIST_NCLASSES);
+ GGML_ASSERT(model.dense_bias->ne[1] == 1);
+ GGML_ASSERT(model.dense_bias->ne[2] == 1);
+ GGML_ASSERT(model.dense_bias->ne[3] == 1);
+ } else {
+ fprintf(stderr, "%s: unknown model arch: %s\n", __func__, model.arch.c_str());
+ }
+ fprintf(stderr, "%s: successfully loaded weights from %s\n", __func__, fname.c_str());
+ return model;
+}
+
+mnist_model mnist_model_init_random(const std::string & arch) {
+ mnist_model model;
+ model.arch = arch;
+
+ std::random_device rd{};
+ std::mt19937 gen{rd()};
+ std::normal_distribution<float> nd{0.0f, 1e-2f};
+ std::vector<ggml_tensor *> init_tensors;
+
+ if (model.arch == "mnist-fc") {
+ fprintf(stderr, "%s: initializing random weights for a fully connected model\n", __func__);
+
+ model.fc1_weight = ggml_new_tensor_2d(model.ctx_weight, GGML_TYPE_F32, MNIST_NINPUT, MNIST_NHIDDEN);
+ model.fc1_bias = ggml_new_tensor_1d(model.ctx_weight, GGML_TYPE_F32, MNIST_NHIDDEN);
+ model.fc2_weight = ggml_new_tensor_2d(model.ctx_weight, GGML_TYPE_F32, MNIST_NHIDDEN, MNIST_NCLASSES);
+ model.fc2_bias = ggml_new_tensor_1d(model.ctx_weight, GGML_TYPE_F32, MNIST_NCLASSES);
+
+ ggml_set_name(model.fc1_weight, "fc1.weight");
+ ggml_set_name(model.fc1_bias, "fc1.bias");
+ ggml_set_name(model.fc2_weight, "fc2.weight");
+ ggml_set_name(model.fc2_bias, "fc2.bias");
+
+ init_tensors.push_back(model.fc1_weight);
+ init_tensors.push_back(model.fc1_bias);
+ init_tensors.push_back(model.fc2_weight);
+ init_tensors.push_back(model.fc2_bias);
+ } else if (model.arch == "mnist-cnn") {
+ model.conv1_kernel = ggml_new_tensor_4d(model.ctx_weight, GGML_TYPE_F32, 3, 3, 1, MNIST_CNN_NCB);
+ model.conv1_bias = ggml_new_tensor_3d(model.ctx_weight, GGML_TYPE_F32, 1, 1, MNIST_CNN_NCB);
+ model.conv2_kernel = ggml_new_tensor_4d(model.ctx_weight, GGML_TYPE_F32, 3, 3, MNIST_CNN_NCB, MNIST_CNN_NCB*2);
+ model.conv2_bias = ggml_new_tensor_3d(model.ctx_weight, GGML_TYPE_F32, 1, 1, MNIST_CNN_NCB*2);
+ model.dense_weight = ggml_new_tensor_2d(model.ctx_weight, GGML_TYPE_F32, (MNIST_HW/4)*(MNIST_HW/4)*(MNIST_CNN_NCB*2), MNIST_NCLASSES);
+ model.dense_bias = ggml_new_tensor_1d(model.ctx_weight, GGML_TYPE_F32, MNIST_NCLASSES);
+
+ ggml_set_name(model.conv1_kernel, "conv1.kernel");
+ ggml_set_name(model.conv1_bias, "conv1.bias");
+ ggml_set_name(model.conv2_kernel, "conv2.kernel");
+ ggml_set_name(model.conv2_bias, "conv2.bias");
+ ggml_set_name(model.dense_weight, "dense.weight");
+ ggml_set_name(model.dense_bias, "dense.bias");
+
+ init_tensors.push_back(model.conv1_kernel);
+ init_tensors.push_back(model.conv1_bias);
+ init_tensors.push_back(model.conv2_kernel);
+ init_tensors.push_back(model.conv2_bias);
+ init_tensors.push_back(model.dense_weight);
+ init_tensors.push_back(model.dense_bias);
+ } else {
+ fprintf(stderr, "%s: unknown model arch: %s\n", __func__, model.arch.c_str());
+ }
+
+ for (ggml_tensor * t : init_tensors) {
+ GGML_ASSERT(t->type == GGML_TYPE_F32);
+ float * data = ggml_get_data_f32(t);
+ const int64_t ne = ggml_nelements(t);
+
+ for (int64_t i = 0; i < ne; ++i) {
+ data[i] = nd(gen);
+ }
+ }
+
+ return model;
+}
+
+void mnist_model_build(mnist_model & model, const int nbatch) {
+ model.nbatch = nbatch;
+
+ if (model.arch == "mnist-fc") {
+ ggml_set_param(model.ctx_compute, model.fc1_weight);
+ ggml_set_param(model.ctx_compute, model.fc1_bias);
+ ggml_set_param(model.ctx_compute, model.fc2_weight);
+ ggml_set_param(model.ctx_compute, model.fc2_bias);
+
+ model.images = ggml_new_tensor_2d(model.ctx_compute, GGML_TYPE_F32, MNIST_NINPUT, model.nbatch);
+ ggml_set_input(model.images);
+ ggml_set_name(model.images, "images");
+
+ ggml_tensor * fc1 = ggml_relu(model.ctx_compute, ggml_add(model.ctx_compute,
+ ggml_mul_mat(model.ctx_compute, model.fc1_weight, model.images),
+ model.fc1_bias));
+ model.logits = ggml_add(model.ctx_compute,
+ ggml_mul_mat(model.ctx_compute, model.fc2_weight, fc1),
+ model.fc2_bias);
+ } else if (model.arch == "mnist-cnn") {
+ ggml_set_param(model.ctx_compute, model.conv1_kernel);
+ ggml_set_param(model.ctx_compute, model.conv1_bias);
+ ggml_set_param(model.ctx_compute, model.conv2_kernel);
+ ggml_set_param(model.ctx_compute, model.conv2_bias);
+ ggml_set_param(model.ctx_compute, model.dense_weight);
+ ggml_set_param(model.ctx_compute, model.dense_bias);
+
+ model.images = ggml_new_tensor_4d(model.ctx_compute, GGML_TYPE_F32, 28, 28, 1, model.nbatch);
+ ggml_set_input(model.images);
+ ggml_set_name(model.images, "images");
+
+ struct ggml_tensor * conv1_out = ggml_relu(model.ctx_compute, ggml_add(model.ctx_compute,
+ ggml_conv_2d(model.ctx_compute, model.conv1_kernel, model.images, 1, 1, 1, 1, 1, 1),
+ model.conv1_bias));
+ GGML_ASSERT(conv1_out->ne[0] == MNIST_HW);
+ GGML_ASSERT(conv1_out->ne[1] == MNIST_HW);
+ GGML_ASSERT(conv1_out->ne[2] == MNIST_CNN_NCB);
+ GGML_ASSERT(conv1_out->ne[3] == model.nbatch);
+
+ struct ggml_tensor * conv2_in = ggml_pool_2d(model.ctx_compute, conv1_out, GGML_OP_POOL_MAX, 2, 2, 2, 2, 0, 0);
+ GGML_ASSERT(conv2_in->ne[0] == MNIST_HW/2);
+ GGML_ASSERT(conv2_in->ne[1] == MNIST_HW/2);
+ GGML_ASSERT(conv2_in->ne[2] == MNIST_CNN_NCB);
+ GGML_ASSERT(conv2_in->ne[3] == model.nbatch);
+
+ struct ggml_tensor * conv2_out = ggml_relu(model.ctx_compute, ggml_add(model.ctx_compute,
+ ggml_conv_2d(model.ctx_compute, model.conv2_kernel, conv2_in, 1, 1, 1, 1, 1, 1),
+ model.conv2_bias));
+ GGML_ASSERT(conv2_out->ne[0] == MNIST_HW/2);
+ GGML_ASSERT(conv2_out->ne[1] == MNIST_HW/2);
+ GGML_ASSERT(conv2_out->ne[2] == MNIST_CNN_NCB*2);
+ GGML_ASSERT(conv2_out->ne[3] == model.nbatch);
+
+ struct ggml_tensor * dense_in = ggml_pool_2d(model.ctx_compute, conv2_out, GGML_OP_POOL_MAX, 2, 2, 2, 2, 0, 0);
+ GGML_ASSERT(dense_in->ne[0] == MNIST_HW/4);
+ GGML_ASSERT(dense_in->ne[1] == MNIST_HW/4);
+ GGML_ASSERT(dense_in->ne[2] == MNIST_CNN_NCB*2);
+ GGML_ASSERT(dense_in->ne[3] == model.nbatch);
+
+ dense_in = ggml_reshape_2d(model.ctx_compute,
+ ggml_cont(model.ctx_compute, ggml_permute(model.ctx_compute, dense_in, 1, 2, 0, 3)),
+ (MNIST_HW/4)*(MNIST_HW/4)*(MNIST_CNN_NCB*2), model.nbatch);
+ GGML_ASSERT(dense_in->ne[0] == (MNIST_HW/4)*(MNIST_HW/4)*(MNIST_CNN_NCB*2));
+ GGML_ASSERT(dense_in->ne[1] == model.nbatch);
+ GGML_ASSERT(dense_in->ne[2] == 1);
+ GGML_ASSERT(dense_in->ne[3] == 1);
+
+ model.logits = ggml_add(model.ctx_compute, ggml_mul_mat(model.ctx_compute, model.dense_weight, dense_in), model.dense_bias);
+ } else {
+ GGML_ASSERT(false);
+ }
+
+ ggml_set_output(model.logits);
+ ggml_set_name(model.logits, "logits");
+ GGML_ASSERT(model.logits->type == GGML_TYPE_F32);
+ GGML_ASSERT(model.logits->ne[0] == MNIST_NCLASSES);
+ GGML_ASSERT(model.logits->ne[1] == model.nbatch);
+ GGML_ASSERT(model.logits->ne[2] == 1);
+ GGML_ASSERT(model.logits->ne[3] == 1);
+
+ model.probs = ggml_soft_max(model.ctx_compute, model.logits);
+ ggml_set_output(model.probs);
+ ggml_set_name(model.probs, "probs");
+ GGML_ASSERT(model.probs->type == GGML_TYPE_F32);
+ GGML_ASSERT(model.probs->ne[0] == MNIST_NCLASSES);
+ GGML_ASSERT(model.probs->ne[1] == model.nbatch);
+ GGML_ASSERT(model.probs->ne[2] == 1);
+ GGML_ASSERT(model.probs->ne[3] == 1);
+
+ model.labels = ggml_new_tensor_2d(model.ctx_compute, GGML_TYPE_F32, MNIST_NCLASSES, model.nbatch);
+ ggml_set_input(model.labels);
+ ggml_set_name(model.labels, "labels");
+
+ model.loss = ggml_cross_entropy_loss(model.ctx_compute, model.logits, model.labels);
+ ggml_set_output(model.loss);
+ ggml_set_name(model.loss, "loss");
+ GGML_ASSERT(model.loss->type == GGML_TYPE_F32);
+ GGML_ASSERT(model.loss->ne[0] == 1);
+ GGML_ASSERT(model.loss->ne[1] == 1);
+ GGML_ASSERT(model.loss->ne[2] == 1);
+ GGML_ASSERT(model.loss->ne[3] == 1);
+}
+
+mnist_eval_result mnist_model_eval(const mnist_model & model, const float * images, const float * labels, const int nex, const int nthreads) {
+ mnist_eval_result result;
+
+ struct ggml_cgraph * gf = ggml_new_graph(model.ctx_compute);
+ ggml_build_forward_expand(gf, model.loss);
+
+ {
+ const int64_t t_start_us = ggml_time_us();
+
+ GGML_ASSERT(nex % model.nbatch == 0);
+ for (int iex0 = 0; iex0 < nex; iex0 += model.nbatch) {
+ memcpy(model.images->data, images + iex0*MNIST_NINPUT, ggml_nbytes(model.images));
+ memcpy(model.labels->data, labels + iex0*MNIST_NCLASSES, ggml_nbytes(model.labels));
+ ggml_graph_compute_with_ctx(model.ctx_compute, gf, nthreads);
+
+ result.loss.push_back(*ggml_get_data_f32(model.loss));
+
+ for (int iexb = 0; iexb < model.nbatch; ++iexb) {
+ const float * logits_data = ggml_get_data_f32(model.logits) + iexb*MNIST_NCLASSES;
+ result.pred.push_back(std::max_element(logits_data, logits_data + MNIST_NCLASSES) - logits_data);
+ }
+ }
+
+ const int64_t t_total_us = ggml_time_us() - t_start_us;
+ const double t_total_ms = 1e-3*t_total_us;
+ fprintf(stderr, "%s: model evaluation on %d images took %.2lf ms, %.2lf us/image\n",
+ __func__, nex, t_total_ms, (double) t_total_us/nex);
+ }
+
+ result.success = true;
+ return result;
+}
+
+void mnist_model_train(mnist_model & model, const float * images, const float * labels, const int nex, const int nthreads) {
+ const int64_t t_start_us = ggml_time_us();
+
+ struct ggml_cgraph * gf = ggml_new_graph_custom(model.ctx_compute, 16384, true);
+ ggml_build_forward_expand(gf, model.loss);
+
+ struct ggml_cgraph * gb = ggml_graph_dup(model.ctx_compute, gf);
+ ggml_build_backward_expand(model.ctx_compute, gf, gb, true);
+
+ struct ggml_opt_context opt_ctx;
+ struct ggml_opt_params opt_pars = ggml_opt_default_params(GGML_OPT_TYPE_ADAM);
+ opt_pars.print_forward_graph = false;
+ opt_pars.print_backward_graph = false;
+ opt_pars.n_threads = nthreads;
+ opt_pars.adam.n_iter = 1; // per call of ggml_opt_resume_g
+ ggml_opt_init(model.ctx_compute, &opt_ctx, opt_pars, 0);
+
+ for (int epoch = 0; epoch < 20; ++epoch) {
+ fprintf(stderr, "%s: epoch %d start...", __func__, epoch);
+ const int64_t t_start_us = ggml_time_us();
+ mnist_eval_result result;
+ for (int iex0 = 0; iex0 < nex; iex0 += model.nbatch) {
+ memcpy(model.images->data, images + iex0*MNIST_NINPUT, ggml_nbytes(model.images));
+ memcpy(model.labels->data, labels + iex0*MNIST_NCLASSES, ggml_nbytes(model.labels));
+
+ enum ggml_opt_result opt_result = ggml_opt_resume_g(model.ctx_compute, &opt_ctx, model.loss, gf, gb, NULL, NULL);
+ GGML_ASSERT(opt_result == GGML_OPT_RESULT_OK || opt_result == GGML_OPT_RESULT_DID_NOT_CONVERGE);
+
+ result.loss.push_back(*ggml_get_data_f32(model.loss));
+
+ for (int iexb = 0; iexb < model.nbatch; ++iexb) {
+ const float * ptr_p = (const float *) model.logits->data + iexb*MNIST_NCLASSES;
+ result.pred.push_back(std::max_element(ptr_p, ptr_p + MNIST_NCLASSES) - ptr_p);
+ }
+ }
+
+ const double loss_mean = mnist_loss(result).first;
+ const double percent_correct = 100.0 * mnist_accuracy(result, labels).first;
+
+ const int64_t t_epoch_us = ggml_time_us() - t_start_us;
+ const double t_epoch_s = 1e-6*t_epoch_us;
+ fprintf(stderr, "done, took %.2lfs, train_loss=%.6lf, train_acc=%.2f%%\n", t_epoch_s, loss_mean, percent_correct);
+ }
+
+ const int64_t t_total_us = ggml_time_us() - t_start_us;
+ const double t_total_s = 1e-6*t_total_us;
+ fprintf(stderr, "%s: training took %.2lfs\n", __func__, t_total_s);
+
+ std::string fname = model.arch + "-f32.ggml";
+ fprintf(stderr, "%s: saving the ggml graph for the forward pass to %s\n", __func__, fname.c_str());
+ ggml_graph_export(gf, fname.c_str());
+}
+
+void mnist_model_save(mnist_model & model, const std::string & fname) {
+ printf("%s: saving model to '%s'\n", __func__, fname.c_str());
+
+ gguf_context * gguf_ctx = gguf_init_empty();
+ gguf_set_val_str(gguf_ctx, "general.architecture", model.arch.c_str());
+
+ if (model.arch == "mnist-fc") {
+ gguf_add_tensor(gguf_ctx, model.fc1_weight);
+ gguf_add_tensor(gguf_ctx, model.fc1_bias);
+ gguf_add_tensor(gguf_ctx, model.fc2_weight);
+ gguf_add_tensor(gguf_ctx, model.fc2_bias);
+ } else if (model.arch == "mnist-cnn") {
+ gguf_add_tensor(gguf_ctx, model.conv1_kernel);
+ gguf_add_tensor(gguf_ctx, model.conv1_bias);
+ gguf_add_tensor(gguf_ctx, model.conv2_kernel);
+ gguf_add_tensor(gguf_ctx, model.conv2_bias);
+ gguf_add_tensor(gguf_ctx, model.dense_weight);
+ gguf_add_tensor(gguf_ctx, model.dense_bias);
+ } else {
+ GGML_ASSERT(false);
+ }
+ gguf_write_to_file(gguf_ctx, fname.c_str(), false);
+}
+
+std::pair<double, double> mnist_loss(const mnist_eval_result & result) {
+ const size_t nbatches = result.loss.size();
+ GGML_ASSERT(nbatches >= 1);
+
+ double sum = 0.0;
+ double sum_squared = 0.0;
+
+ for (const float & loss : result.loss) {
+ sum += loss;
+ sum_squared += loss*loss;
+ }
+
+ const double mean = sum/nbatches;
+ const double uncertainty = sqrt((sum_squared/nbatches - mean*mean) / (nbatches - 1));
+
+ return std::make_pair(mean, uncertainty);
+}
+
+std::pair<double, double> mnist_accuracy(const mnist_eval_result & result, const float * labels) {
+ const size_t nex = result.pred.size();
+ GGML_ASSERT(nex >= 1);
+
+ size_t ncorrect = 0;
+ for (size_t iex = 0; iex < nex; ++iex) {
+ const float * labels_iex = labels + iex*MNIST_NCLASSES;
+ const int32_t label = std::max_element(labels_iex, labels_iex + MNIST_NCLASSES) - labels_iex;
+
+ ncorrect += result.pred[iex] == label;
+ }
+
+ const double fraction_correct = ((double) ncorrect) / ((double) nex);
+ const double uncertainty = sqrt(fraction_correct * (1.0 - fraction_correct) / (nex - 1));
+
+ return std::make_pair(fraction_correct, uncertainty);
+}
+
+#ifdef __cplusplus
+extern "C" {
+#endif
+
+int wasm_eval(uint8_t * digitPtr) {
+ std::vector<float> digit(digitPtr, digitPtr + MNIST_NINPUT);
+ std::vector<float> labels(MNIST_NCLASSES);
+
+ mnist_model model = mnist_model_init_from_file("mnist-f32.gguf");
+ mnist_model_build(model, 1);
+ mnist_eval_result result = mnist_model_eval(model, digit.data(), labels.data(), 1, 1);
+
+ return result.pred[0];
+}
+
+int wasm_random_digit(char * digitPtr) {
+ auto fin = std::ifstream("t10k-images-idx3-ubyte", std::ios::binary);
+ if (!fin) {
+ fprintf(stderr, "failed to open digits file\n");
+ return 0;
+ }
+ srand(time(NULL));
+
+ // Seek to a random digit: 16-byte header + 28*28 * (random 0 - 10000)
+ fin.seekg(16 + MNIST_NINPUT * (rand() % MNIST_NTEST));
+ fin.read(digitPtr, MNIST_NINPUT);
+
+ return 1;
+}
+
+#ifdef __cplusplus
+}
+#endif
--- /dev/null
+#include <string>
+#include <vector>
+
+#include "ggml.h"
+
+#define MNIST_NTRAIN 60000
+#define MNIST_NTEST 10000
+#define MNIST_NBATCH 500
+
+static_assert(MNIST_NTRAIN % MNIST_NBATCH == 0, "MNIST_NTRAIN % MNIST_BATCH != 0");
+static_assert(MNIST_NTEST % MNIST_NBATCH == 0, "MNIST_NTRAIN % MNIST_BATCH != 0");
+
+#define MNIST_HW 28
+#define MNIST_NINPUT (MNIST_HW*MNIST_HW)
+#define MNIST_NCLASSES 10
+
+#define MNIST_NHIDDEN 500
+
+// NCB = number of channels base
+#define MNIST_CNN_NCB 8
+
+struct mnist_model {
+ std::string arch;
+ int nbatch;
+
+ struct ggml_tensor * images = nullptr;
+ struct ggml_tensor * labels = nullptr;
+ struct ggml_tensor * logits = nullptr;
+ struct ggml_tensor * probs = nullptr;
+ struct ggml_tensor * loss = nullptr;
+
+ struct ggml_tensor * fc1_weight = nullptr;
+ struct ggml_tensor * fc1_bias = nullptr;
+ struct ggml_tensor * fc2_weight = nullptr;
+ struct ggml_tensor * fc2_bias = nullptr;
+
+ struct ggml_tensor * conv1_kernel = nullptr;
+ struct ggml_tensor * conv1_bias = nullptr;
+ struct ggml_tensor * conv2_kernel = nullptr;
+ struct ggml_tensor * conv2_bias = nullptr;
+ struct ggml_tensor * dense_weight = nullptr;
+ struct ggml_tensor * dense_bias = nullptr;
+
+ static const size_t size_weight = 100 * 1024*1024;
+ static const size_t size_compute = 1 * 1024*1024*1024;
+
+ void * buf_weight = nullptr;
+ struct ggml_context * ctx_weight = nullptr;
+ void * buf_compute = nullptr;
+ struct ggml_context * ctx_compute = nullptr;
+
+ mnist_model() {
+ buf_weight = malloc(size_weight);
+ {
+ struct ggml_init_params params = {
+ /*.mem_size =*/ size_weight,
+ /*.mem_buffer =*/ buf_weight,
+ /*.no_alloc =*/ false,
+ };
+ ctx_weight = ggml_init(params);
+ }
+
+ buf_compute = malloc(size_compute);
+ {
+ struct ggml_init_params params = {
+ /*.mem_size =*/ size_compute,
+ /*.mem_buffer =*/ buf_compute,
+ /*.no_alloc =*/ false,
+ };
+ ctx_compute = ggml_init(params);
+ }
+ }
+
+ ~mnist_model() {
+ ggml_free(ctx_weight);
+ ggml_free(ctx_compute);
+
+ free(buf_weight);
+ free(buf_compute);
+ }
+};
+
+struct mnist_eval_result {
+ bool success = false;
+
+ std::vector<float> loss;
+ std::vector<int32_t> pred;
+};
+
+bool mnist_image_load(const std::string & fname, float * buf, const int nex);
+void mnist_image_print(FILE * f, const float * image);
+bool mnist_label_load(const std::string & fname, float * buf, const int nex);
+
+mnist_eval_result mnist_graph_eval(const std::string & fname, const float * images, const float * labels, const int nex, const int nthreads);
+
+mnist_model mnist_model_init_from_file(const std::string & fname);
+mnist_model mnist_model_init_random(const std::string & arch);
+void mnist_model_build(mnist_model & model, const int nbatch);
+mnist_eval_result mnist_model_eval(const mnist_model & model, const float * images, const float * labels, const int nex, const int nthreads);
+void mnist_model_train(mnist_model & model, const float * images, const float * labels, const int nex, const int nthreads);
+void mnist_model_save(mnist_model & model, const std::string & fname);
+
+std::pair<double, double> mnist_loss(const mnist_eval_result & result);
+std::pair<double, double> mnist_accuracy(const mnist_eval_result & result, const float * labels);
--- /dev/null
+#include "ggml.h"
+
+#include "mnist-common.h"
+
+#include <cmath>
+#include <cstdint>
+#include <cstdio>
+#include <cstring>
+#include <ctime>
+#include <string>
+#include <thread>
+#include <vector>
+
+#if defined(_MSC_VER)
+#pragma warning(disable: 4244 4267) // possible loss of data
+#endif
+
+int main(int argc, char ** argv) {
+ srand(time(NULL));
+ ggml_time_init();
+
+ if (argc != 4) {
+ fprintf(stderr, "Usage: %s mnist-fc-f32.gguf data/MNIST/raw/t10k-images-idx3-ubyte data/MNIST/raw/t10k-labels-idx1-ubyte\n", argv[0]);
+ exit(1);
+ }
+
+ std::vector<float> images;
+ images.resize(MNIST_NTEST*MNIST_NINPUT);
+ if (!mnist_image_load(argv[2], images.data(), MNIST_NTEST)) {
+ return 1;
+ }
+
+ std::vector<float> labels;
+ labels.resize(MNIST_NTEST*MNIST_NCLASSES);
+ if (!mnist_label_load(argv[3], labels.data(), MNIST_NTEST)) {
+ return 1;
+ }
+
+ const int nthreads = std::thread::hardware_concurrency();
+
+ const int iex = rand() % MNIST_NTEST;
+ const std::vector<float> digit(images.begin() + iex*MNIST_NINPUT, images.begin() + (iex+1)*MNIST_NINPUT);
+
+ mnist_image_print(stdout, images.data() + iex*MNIST_NINPUT);
+
+ mnist_eval_result result_eval = mnist_graph_eval(argv[1], images.data(), labels.data(), MNIST_NTEST, nthreads);
+ if (result_eval.success) {
+ fprintf(stdout, "%s: predicted digit is %d\n", __func__, result_eval.pred[iex]);
+
+ std::pair<double, double> result_loss = mnist_loss(result_eval);
+ fprintf(stdout, "%s: test_loss=%.6lf+-%.6lf\n", __func__, result_loss.first, result_loss.second);
+
+ std::pair<double, double> result_acc = mnist_accuracy(result_eval, labels.data());
+ fprintf(stdout, "%s: test_acc=%.2lf+-%.2lf%%\n", __func__, 100.0*result_acc.first, 100.0*result_acc.second);
+
+ return 0;
+ }
+
+ const int64_t t_start_us = ggml_time_us();
+
+ mnist_model model = mnist_model_init_from_file(argv[1]);
+
+ mnist_model_build(model, MNIST_NBATCH);
+
+ const int64_t t_load_us = ggml_time_us() - t_start_us;
+
+ fprintf(stdout, "%s: loaded model in %.2lf ms\n", __func__, t_load_us / 1000.0);
+ result_eval = mnist_model_eval(model, images.data(), labels.data(), MNIST_NTEST, nthreads);
+ fprintf(stdout, "%s: predicted digit is %d\n", __func__, result_eval.pred[iex]);
+
+ std::pair<double, double> result_loss = mnist_loss(result_eval);
+ fprintf(stdout, "%s: test_loss=%.6lf+-%.6lf\n", __func__, result_loss.first, result_loss.second);
+
+ std::pair<double, double> result_acc = mnist_accuracy(result_eval, labels.data());
+ fprintf(stdout, "%s: test_acc=%.2lf+-%.2lf%%\n", __func__, 100.0*result_acc.first, 100.0*result_acc.second);
+
+ return 0;
+}
--- /dev/null
+#!/usr/bin/env python3
+import sys
+from time import time
+import gguf
+import numpy as np
+import tensorflow as tf
+from tensorflow import keras
+from tensorflow.keras import layers
+
+
+def train(model_path):
+ # Model / data parameters
+ num_classes = 10
+ input_shape = (28, 28, 1)
+
+ # Load the data and split it between train and test sets
+ (x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
+
+ # Scale images to the [0, 1] range
+ x_train = x_train.astype("float32") / 255
+ x_test = x_test.astype("float32") / 255
+ x_train = np.expand_dims(x_train, -1)
+ x_test = np.expand_dims(x_test, -1)
+ print("x_train shape:", x_train.shape)
+ print(x_train.shape[0], "train samples")
+ print(x_test.shape[0], "test samples")
+
+ # convert class vectors to binary class matrices
+ y_train = keras.utils.to_categorical(y_train, num_classes)
+ y_test = keras.utils.to_categorical(y_test, num_classes)
+
+ model = keras.Sequential(
+ [
+ keras.Input(shape=input_shape, dtype=tf.float32),
+ layers.Conv2D(8, kernel_size=(3, 3), padding="same", activation="relu", dtype=tf.float32),
+ layers.MaxPooling2D(pool_size=(2, 2)),
+ layers.Conv2D(16, kernel_size=(3, 3), padding="same", activation="relu", dtype=tf.float32),
+ layers.MaxPooling2D(pool_size=(2, 2)),
+ layers.Flatten(),
+ layers.Dense(num_classes, activation="softmax", dtype=tf.float32),
+ ]
+ )
+
+ model.summary()
+ batch_size = 500
+ epochs = 20
+ model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
+
+ t_start = time()
+ model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
+ print(f"Training took {time()-t_start:.2f}s")
+
+ score = model.evaluate(x_test, y_test, verbose=0)
+ print(f"Test loss: {score[0]:.6f}")
+ print(f"Test accuracy: {100*score[1]:.2f}%")
+
+ gguf_writer = gguf.GGUFWriter(model_path, "mnist-cnn")
+
+ conv1_kernel = model.layers[0].weights[0].numpy()
+ conv1_kernel = np.moveaxis(conv1_kernel, [2, 3], [0, 1])
+ gguf_writer.add_tensor("conv1.kernel", conv1_kernel, raw_shape=(8, 1, 3, 3))
+
+ conv1_bias = model.layers[0].weights[1].numpy()
+ conv1_bias = np.repeat(conv1_bias, 28*28)
+ gguf_writer.add_tensor("conv1.bias", conv1_bias, raw_shape=(1, 8, 28, 28))
+
+ conv2_kernel = model.layers[2].weights[0].numpy()
+ conv2_kernel = np.moveaxis(conv2_kernel, [0, 1, 2, 3], [2, 3, 1, 0])
+ gguf_writer.add_tensor("conv2.kernel", conv2_kernel, raw_shape=(16, 8, 3, 3))
+
+ conv2_bias = model.layers[2].weights[1].numpy()
+ conv2_bias = np.repeat(conv2_bias, 14*14)
+ gguf_writer.add_tensor("conv2.bias", conv2_bias, raw_shape=(1, 16, 14, 14))
+
+ dense_weight = model.layers[-1].weights[0].numpy()
+ dense_weight = dense_weight.transpose()
+ gguf_writer.add_tensor("dense.weight", dense_weight, raw_shape=(10, 7*7*16))
+
+ dense_bias = model.layers[-1].weights[1].numpy()
+ gguf_writer.add_tensor("dense.bias", dense_bias)
+
+ gguf_writer.write_header_to_file()
+ gguf_writer.write_kv_data_to_file()
+ gguf_writer.write_tensors_to_file()
+ gguf_writer.close()
+ print(f"GGUF model saved to '{model_path}'")
+
+
+if __name__ == '__main__':
+ if len(sys.argv) != 2:
+ print(f"Usage: {sys.argv[0]} <model_path>")
+ sys.exit(1)
+ train(sys.argv[1])
--- /dev/null
+import gguf
+import numpy as np
+import torch
+import torch.nn as nn
+import torchvision.datasets as dsets
+import torchvision.transforms as transforms
+from torch.autograd import Variable
+
+import sys
+from time import time
+
+input_size = 784 # img_size = (28,28) ---> 28*28=784 in total
+hidden_size = 500 # number of nodes at hidden layer
+num_classes = 10 # number of output classes discrete range [0,9]
+num_epochs = 20 # number of times which the entire dataset is passed throughout the model
+batch_size = 500 # the size of input data took for one iteration
+lr = 1e-3 # size of step
+
+
+class Net(nn.Module):
+ def __init__(self, input_size, hidden_size, num_classes):
+ super(Net, self).__init__()
+ self.fc1 = nn.Linear(input_size, hidden_size)
+ self.relu = nn.ReLU()
+ self.fc2 = nn.Linear(hidden_size, num_classes)
+
+ def forward(self, x):
+ out = self.fc1(x)
+ out = self.relu(out)
+ out = self.fc2(out)
+ return out
+
+
+def train(model_path):
+ train_data = dsets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)
+ test_data = dsets.MNIST(root='./data', train=False, transform=transforms.ToTensor())
+
+ assert len(train_data) == 60000
+ assert len(test_data) == 10000
+
+ train_gen = torch.utils.data.DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)
+ test_gen = torch.utils.data.DataLoader(dataset=test_data, batch_size=batch_size, shuffle=False)
+
+ net = Net(input_size, hidden_size, num_classes)
+
+ if torch.cuda.is_available():
+ net.cuda()
+
+ loss_function = nn.CrossEntropyLoss()
+ optimizer = torch.optim.Adam(net.parameters(), lr=lr)
+
+ t_start = time()
+ for epoch in range(num_epochs):
+ loss_history = []
+ ncorrect = 0
+
+ for i, (images, labels) in enumerate(train_gen):
+ images = Variable(images.view(-1, 28*28))
+ labels = Variable(labels)
+
+ if torch.cuda.is_available():
+ images = images.cuda()
+ labels = labels.cuda()
+
+ optimizer.zero_grad()
+ outputs = net(images)
+ loss = loss_function(outputs, labels)
+
+ loss_history.append(loss.cpu().data)
+ _, predictions = torch.max(outputs, 1)
+ ncorrect += (predictions == labels).sum()
+
+ loss.backward()
+ optimizer.step()
+
+ if (i + 1)*batch_size % 10000 == 0:
+ loss_mean = np.mean(loss_history)
+ accuracy = ncorrect / ((i + 1) * batch_size)
+ print(
+ f"Epoch [{epoch+1:02d}/{num_epochs}], "
+ f"Step [{(i+1)*batch_size:05d}/{len(train_data)}], "
+ f"Loss: {loss_mean:.4f}, Accuracy: {100*accuracy:.2f}%")
+ print()
+ print(f"Training took {time()-t_start:.2f}s")
+
+ loss_history = []
+ ncorrect = 0
+
+ for i, (images, labels) in enumerate(test_gen):
+ images = Variable(images.view(-1, 28*28))
+ labels = Variable(labels)
+
+ if torch.cuda.is_available():
+ images = images.cuda()
+ labels = labels.cuda()
+
+ outputs = net(images)
+ loss = loss_function(outputs, labels)
+
+ loss_history.append(loss.cpu().data)
+ _, predictions = torch.max(outputs, 1)
+ ncorrect += (predictions == labels).sum().cpu().numpy()
+
+ loss_mean = np.mean(loss_history)
+ loss_uncertainty = np.std(loss_history) / np.sqrt(len(loss_history) - 1)
+ accuracy_mean = ncorrect / (len(test_gen) * batch_size)
+ accuracy_uncertainty = np.sqrt(accuracy_mean * (1.0 - accuracy_mean) / (len(test_gen) * batch_size))
+ print()
+ print(f"Test loss: {loss_mean:.6f}+-{loss_uncertainty:.6f}, Test accuracy: {100*accuracy_mean:.2f}+-{100*accuracy_uncertainty:.2f}%")
+
+ gguf_writer = gguf.GGUFWriter(model_path, "mnist-fc")
+
+ print()
+ print(f"Model tensors saved to {model_path}:")
+ for tensor_name in net.state_dict().keys():
+ data = net.state_dict()[tensor_name].squeeze().cpu().numpy()
+ print(tensor_name, "\t", data.shape)
+ gguf_writer.add_tensor(tensor_name, data)
+
+ gguf_writer.write_header_to_file()
+ gguf_writer.write_kv_data_to_file()
+ gguf_writer.write_tensors_to_file()
+ gguf_writer.close()
+
+
+if __name__ == '__main__':
+ if len(sys.argv) != 2:
+ print(f"Usage: {sys.argv[0]} <model_path>")
+ sys.exit(1)
+ train(sys.argv[1])
--- /dev/null
+#include "mnist-common.h"
+
+#include <cmath>
+#include <cstdio>
+#include <cstring>
+#include <ctime>
+#include <string>
+#include <thread>
+
+#if defined(_MSC_VER)
+#pragma warning(disable: 4244 4267) // possible loss of data
+#endif
+
+int main(int argc, char ** argv) {
+ if (argc != 5) {
+ fprintf(stderr, "Usage: %s mnist-fc mnist-fc-f32.gguf data/MNIST/raw/train-images-idx3-ubyte data/MNIST/raw/train-labels-idx1-ubyte\n", argv[0]);
+ exit(0);
+ }
+
+ std::vector<float> images;
+ images.resize(MNIST_NTRAIN*MNIST_NINPUT);
+ if (!mnist_image_load(argv[3], images.data(), MNIST_NTRAIN)) {
+ return 1;
+ }
+
+ std::vector<float> labels;
+ labels.resize(MNIST_NTRAIN*MNIST_NCLASSES);
+ if (!mnist_label_load(argv[4], labels.data(), MNIST_NTRAIN)) {
+ return 1;
+ }
+
+ mnist_model model = mnist_model_init_random(argv[1]);
+
+ mnist_model_build(model, MNIST_NBATCH);
+
+ mnist_model_train(model, images.data(), labels.data(), MNIST_NTRAIN, std::thread::hardware_concurrency());
+
+ mnist_model_save(model, argv[2]);
+}
+++ /dev/null
-ggml-model-f32.bin
#include <stdio.h>
#define GGML_FILE_MAGIC 0x67676d6c // "ggml"
-#define GGML_FILE_VERSION 1
+#define GGML_FILE_VERSION 2
#define GGML_QNT_VERSION 2 // bump this on quantization format changes
#define GGML_QNT_VERSION_FACTOR 1000 // do not change this
GGML_OP_CLAMP,
GGML_OP_CONV_TRANSPOSE_1D,
GGML_OP_IM2COL,
+ GGML_OP_IM2COL_BACK,
GGML_OP_CONV_TRANSPOSE_2D,
GGML_OP_POOL_1D,
GGML_OP_POOL_2D,
+ GGML_OP_POOL_2D_BACK,
GGML_OP_UPSCALE, // nearest interpolate
GGML_OP_PAD,
GGML_OP_ARANGE,
float min,
float max);
+ // im2col
+ // converts data into a format that effectively results in a convolution when combined with matrix multiplication
GGML_API struct ggml_tensor * ggml_im2col(
struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- int s0,
- int s1,
- int p0,
- int p1,
- int d0,
- int d1,
- bool is_2D,
- enum ggml_type dst_type);
+ struct ggml_tensor * a, // convolution kernel
+ struct ggml_tensor * b, // data
+ int s0, // stride dimension 0
+ int s1, // stride dimension 1
+ int p0, // padding dimension 0
+ int p1, // padding dimension 1
+ int d0, // dilation dimension 0
+ int d1, // dilation dimension 1
+ bool is_2D,
+ enum ggml_type dst_type);
+
+ GGML_API struct ggml_tensor * ggml_im2col_back(
+ struct ggml_context * ctx,
+ struct ggml_tensor * a, // convolution kernel
+ struct ggml_tensor * b, // gradient of im2col output
+ int64_t * ne, // shape of im2col input
+ int s0, // stride dimension 0
+ int s1, // stride dimension 1
+ int p0, // padding dimension 0
+ int p1, // padding dimension 1
+ int d0, // dilation dimension 0
+ int d1, // dilation dimension 1
+ bool is_2D);
GGML_API struct ggml_tensor * ggml_conv_depthwise_2d(
struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- int s0,
- int s1,
- int p0,
- int p1,
- int d0,
- int d1);
+ struct ggml_tensor * a, // convolution kernel
+ struct ggml_tensor * b, // data
+ int s0, // stride dimension 0
+ int s1, // stride dimension 1
+ int p0, // padding dimension 0
+ int p1, // padding dimension 1
+ int d0, // dilation dimension 0
+ int d1); // dilation dimension 1
GGML_API struct ggml_tensor * ggml_conv_1d(
struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
+ struct ggml_tensor * a, // convolution kernel
+ struct ggml_tensor * b, // data
int s0, // stride
int p0, // padding
int d0); // dilation
// alias for ggml_conv_1d(a, b, s, a->ne[0]/2, d)
GGML_API struct ggml_tensor* ggml_conv_1d_ph(
struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- int s,
- int d);
+ struct ggml_tensor * a, // convolution kernel
+ struct ggml_tensor * b, // data
+ int s, // stride
+ int d); // dilation
GGML_API struct ggml_tensor * ggml_conv_transpose_1d(
struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- int s0,
- int p0,
- int d0);
+ struct ggml_tensor * a, // convolution kernel
+ struct ggml_tensor * b, // data
+ int s0, // stride
+ int p0, // padding
+ int d0); // dilation
GGML_API struct ggml_tensor * ggml_conv_2d(
struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- int s0,
- int s1,
- int p0,
- int p1,
- int d0,
- int d1);
+ struct ggml_tensor * a, // convolution kernel
+ struct ggml_tensor * b, // data
+ int s0, // stride dimension 0
+ int s1, // stride dimension 1
+ int p0, // padding dimension 0
+ int p1, // padding dimension 1
+ int d0, // dilation dimension 0
+ int d1); // dilation dimension 1
// kernel size is a->ne[0] x a->ne[1]
float p0,
float p1);
+ GGML_API struct ggml_tensor * ggml_pool_2d_back(
+ struct ggml_context * ctx,
+ struct ggml_tensor * a,
+ struct ggml_tensor * af, // "a"/input used in forward pass
+ enum ggml_op_pool op,
+ int k0,
+ int k1,
+ int s0,
+ int s1,
+ float p0,
+ float p1);
+
// nearest interpolate
// multiplies ne0 and ne1 by scale factor
// used in stable-diffusion
"CLAMP",
"CONV_TRANSPOSE_1D",
"IM2COL",
+ "IM2COL_BACK",
"CONV_TRANSPOSE_2D",
"POOL_1D",
"POOL_2D",
+ "POOL_2D_BACK",
"UPSCALE",
"PAD",
"ARANGE",
"CROSS_ENTROPY_LOSS_BACK",
};
-static_assert(GGML_OP_COUNT == 76, "GGML_OP_COUNT != 76");
+static_assert(GGML_OP_COUNT == 78, "GGML_OP_COUNT != 78");
static const char * GGML_OP_SYMBOL[GGML_OP_COUNT] = {
"none",
"clamp(x)",
"conv_transpose_1d(x)",
"im2col(x)",
+ "im2col_back(x)",
"conv_transpose_2d(x)",
"pool_1d(x)",
"pool_2d(x)",
+ "pool_2d_back(x)",
"upscale(x)",
"pad(x)",
"arange(start, stop, step)",
"cross_entropy_loss_back(x,y)",
};
-static_assert(GGML_OP_COUNT == 76, "GGML_OP_COUNT != 76");
+static_assert(GGML_OP_COUNT == 78, "GGML_OP_COUNT != 78");
static_assert(GGML_OP_POOL_COUNT == 2, "GGML_OP_POOL_COUNT != 2");
size_t data_size = ggml_row_size(type, ne[0]);
for (int i = 1; i < n_dims; i++) {
+ assert(ne[i] > 0);
data_size *= ne[i];
}
}
struct ggml_object * const obj_new = ggml_new_object(ctx, GGML_OBJECT_TYPE_TENSOR, GGML_TENSOR_SIZE + obj_alloc_size);
+ GGML_ASSERT(obj_new);
// TODO: for recoverable errors, we would need to free the data allocated from the scratch buffer here
bool is_node = false;
if (!inplace && (a->grad || b->grad)) {
- // TODO: support backward pass for broadcasting
- GGML_ASSERT(ggml_are_same_shape(a, b));
is_node = true;
}
GGML_ASSERT(a->ne[2] == b->ne[2]);
} else {
GGML_ASSERT(a->ne[1] == b->ne[1]);
+ GGML_ASSERT(b->ne[3] == 1);
}
bool is_node = false;
- if (a->grad || b->grad) {
- GGML_ABORT("fatal error"); // TODO: implement backward
+ if (/*a->grad ||*/ b->grad) { // a is only used for its shape, not its data
is_node = true;
}
const int64_t OH = is_2D ? ggml_calc_conv_output_size(b->ne[1], a->ne[1], s1, p1, d1) : 0;
const int64_t OW = ggml_calc_conv_output_size(b->ne[0], a->ne[0], s0, p0, d0);
+ GGML_ASSERT((!is_2D || OH > 0) && "b too small compared to a");
+ GGML_ASSERT((OW > 0) && "b too small compared to a");
+
const int64_t ne[4] = {
is_2D ? (a->ne[2] * a->ne[1] * a->ne[0]) : a->ne[1] * a->ne[0],
OW,
return result;
}
+struct ggml_tensor * ggml_im2col_back(
+ struct ggml_context * ctx,
+ struct ggml_tensor * a,
+ struct ggml_tensor * b,
+ int64_t * ne,
+ int s0,
+ int s1,
+ int p0,
+ int p1,
+ int d0,
+ int d1,
+ bool is_2D) {
+
+ bool is_node = false;
+
+ if (/*a->grad ||*/ b->grad) { // a is only used for its shape, not its data
+ is_node = true;
+ }
+
+ struct ggml_tensor * result = ggml_new_tensor(ctx, GGML_TYPE_F32, 4, ne);
+ int32_t params[] = { s0, s1, p0, p1, d0, d1, (is_2D ? 1 : 0) };
+ ggml_set_op_params(result, params, sizeof(params));
+
+ result->op = GGML_OP_IM2COL_BACK;
+ result->grad = is_node ? ggml_dup_tensor(ctx, result) : NULL;
+ result->src[0] = a;
+ result->src[1] = b;
+
+ return result;
+}
+
// a: [OC,IC, KH, KW]
// b: [N, IC, IH, IW]
// result: [N, OC, OH, OW]
int p1,
int d0,
int d1) {
- struct ggml_tensor * im2col = ggml_im2col(ctx, a, b, s0, s1, p0, p1, d0, d1, true, GGML_TYPE_F16); // [N, OH, OW, IC * KH * KW]
+ struct ggml_tensor * im2col = ggml_im2col(ctx, a, b, s0, s1, p0, p1, d0, d1, true, a->type); // [N, OH, OW, IC * KH * KW]
struct ggml_tensor * result =
ggml_mul_mat(ctx,
bool is_node = false;
if (a->grad) {
- GGML_ABORT("fatal error"); // TODO: implement backward
is_node = true;
}
struct ggml_tensor * result;
- const int64_t ne[3] = {
+ const int64_t ne[4] = {
ggml_calc_pool_output_size(a->ne[0], k0, s0, p0),
ggml_calc_pool_output_size(a->ne[1], k1, s1, p1),
a->ne[2],
+ a->ne[3],
};
- result = ggml_new_tensor(ctx, GGML_TYPE_F32, 3, ne);
+ result = ggml_new_tensor(ctx, GGML_TYPE_F32, 4, ne);
int32_t params[] = { op, k0, k1, s0, s1, p0, p1 };
ggml_set_op_params(result, params, sizeof(params));
return result;
}
+struct ggml_tensor * ggml_pool_2d_back(
+ struct ggml_context * ctx,
+ struct ggml_tensor * a,
+ struct ggml_tensor * af,
+ enum ggml_op_pool op,
+ int k0,
+ int k1,
+ int s0,
+ int s1,
+ float p0,
+ float p1) {
+
+ bool is_node = false;
+
+ if (a->grad) {
+ is_node = true;
+ }
+
+ struct ggml_tensor * result;
+ result = ggml_new_tensor(ctx, GGML_TYPE_F32, 4, af->ne);
+
+ int32_t params[] = { op, k0, k1, s0, s1, p0, p1 };
+ ggml_set_op_params(result, params, sizeof(params));
+
+ result->op = GGML_OP_POOL_2D_BACK;
+ result->grad = is_node ? ggml_dup_tensor(ctx, result) : NULL;
+ result->src[0] = a;
+ result->src[1] = af;
+ return result;
+}
+
// ggml_upscale
static struct ggml_tensor * ggml_upscale_impl(
}
}
+// ggml_compute_forward_im2col_f32
// src0: kernel [OC, IC, KH, KW]
// src1: image [N, IC, IH, IW]
// dst: result [N, OH, OW, IC*KH*KW]
const struct ggml_tensor * src0 = dst->src[0];
const struct ggml_tensor * src1 = dst->src[1];
- GGML_ASSERT(src0->type == GGML_TYPE_F16);
GGML_ASSERT(src1->type == GGML_TYPE_F32);
GGML_ASSERT( dst->type == GGML_TYPE_F32);
int ofs0 = is_2D ? nb13 : nb12;
int ofs1 = is_2D ? nb12 : nb11;
- GGML_ASSERT(nb00 == sizeof(ggml_fp16_t));
GGML_ASSERT(nb10 == sizeof(float));
// im2col: [N, IC, IH, IW] => [N, OH, OW, IC*KH*KW]
}
+// ggml_compute_forward_im2col_f16
// src0: kernel [OC, IC, KH, KW]
// src1: image [N, IC, IH, IW]
// dst: result [N, OH, OW, IC*KH*KW]
}
}
+// ggml_compute_forward_im2col_back_f32
+
+static void ggml_compute_forward_im2col_back_f32(
+ const struct ggml_compute_params * params,
+ struct ggml_tensor * dst) {
+
+ const struct ggml_tensor * src0 = dst->src[0];
+ const struct ggml_tensor * src1 = dst->src[1];
+
+ GGML_ASSERT(src1->type == GGML_TYPE_F32);
+ GGML_ASSERT( dst->type == GGML_TYPE_F32);
+
+ GGML_TENSOR_BINARY_OP_LOCALS;
+
+ const int32_t s0 = ((const int32_t *)(dst->op_params))[0];
+ const int32_t s1 = ((const int32_t *)(dst->op_params))[1];
+ const int32_t p0 = ((const int32_t *)(dst->op_params))[2];
+ const int32_t p1 = ((const int32_t *)(dst->op_params))[3];
+ const int32_t d0 = ((const int32_t *)(dst->op_params))[4];
+ const int32_t d1 = ((const int32_t *)(dst->op_params))[5];
+ const bool is_2D = ((const int32_t *)(dst->op_params))[6] == 1;
+
+ const int ith = params->ith;
+ const int nth = params->nth;
+
+ const int64_t N = is_2D ? ne3 : ne2;
+ const int64_t IC = is_2D ? ne2 : ne1;
+ const int64_t IH = is_2D ? ne1 : 1;
+ const int64_t IW = ne0;
+
+ const int64_t KH = is_2D ? ne01 : 1;
+ const int64_t KW = ne00;
+
+ const int64_t OH = is_2D ? ne12 : 1;
+ const int64_t OW = ne11;
+
+ int ofs0 = is_2D ? nb3 : nb2;
+ int ofs1 = is_2D ? nb2 : nb1;
+
+ GGML_ASSERT(nb0 == sizeof(float));
+
+ // im2col: [N, IC, IH, IW] => [N, OH, OW, IC*KH*KW]
+ {
+ float * const wdata = (float *) dst->data;
+
+ for (int64_t in = 0; in < N; in++) {
+ for (int64_t iic = ith; iic < IC; iic += nth) {
+ for (int64_t iih = 0; iih < IH; iih++) {
+ for (int64_t iiw = 0; iiw < IW; iiw++) {
+
+ // micro kernel
+ float grad = 0.0f;
+ for (int64_t ikh = 0; ikh < KH; ikh++) {
+ for (int64_t ikw = 0; ikw < KW; ikw++) {
+ // For s0 > 1 some values were skipped over in the forward pass.
+ // These values have tmpw % s0 != 0 and need to be skipped in the backwards pass as well.
+ const int64_t tmpw = (iiw + p0 - ikw*d0);
+ if (tmpw % s0 != 0) {
+ continue;
+ }
+ const int64_t iow = tmpw / s0;
+
+ // Equivalent logic as above except for s1.
+ int64_t ioh;
+ if (is_2D) {
+ const int64_t tmph = iih + p1 - ikh*d1;
+
+ if (tmph % s1 != 0) {
+ continue;
+ }
+
+ ioh = tmph / s1;
+ } else {
+ ioh = 0;
+ }
+
+ if (iow < 0 || iow >= OW || ioh < 0 || ioh >= OH) {
+ continue;
+ }
+
+ const float * const src_data = (const float *) src1->data
+ + (in*OH*OW + ioh*OW + iow)*(IC*KH*KW); // [IC, KH, KW]
+ grad += src_data[iic*(KH*KW) + ikh*KW + ikw];
+ }
+ }
+ float * dst_data = (float *)((char *) wdata + (in*ofs0 + iic*ofs1)); // [IH, IW]
+ dst_data[iih*IW + iiw] = grad;
+ }
+ }
+ }
+ }
+ }
+}
// ggml_compute_forward_conv_transpose_2d
}
}
+// ggml_compute_forward_pool_2d_back
+
+static void ggml_compute_forward_pool_2d_back(
+ const struct ggml_compute_params * params,
+ struct ggml_tensor * dst) {
+
+ const struct ggml_tensor * src = dst->src[0];
+ const struct ggml_tensor * dstf = dst->src[1]; // forward tensor of dst
+
+ assert(dst->type == GGML_TYPE_F32 || dst->type == GGML_TYPE_F16);
+
+ if (params->ith != 0) {
+ return;
+ }
+
+ const int32_t * opts = (const int32_t *)dst->op_params;
+ enum ggml_op_pool op = opts[0];
+ const int k0 = opts[1];
+ const int k1 = opts[2];
+ const int s0 = opts[3];
+ const int s1 = opts[4];
+ const int p0 = opts[5];
+ const int p1 = opts[6];
+
+ char * cdata = (char *) dst->data;
+ const char * cdataf = (const char *) dstf->data;
+ const char * const data_end = cdata + ggml_nbytes(dst);
+
+ GGML_ASSERT(params->ith == 0);
+ memset(cdata, 0, ggml_nbytes(dst));
+
+ const int64_t px = src->ne[0];
+ const int64_t py = src->ne[1];
+ const int64_t pa = px * py;
+
+ const float * splane = (const float *) src->data;
+
+ const int ka = k0 * k1;
+ const int offset0 = -p0;
+ const int offset1 = -p1;
+
+ while (cdata < data_end) {
+ for (int oy = 0; oy < py; ++oy) {
+ const float * const srow = splane + oy * px;
+ for (int ox = 0; ox < px; ++ox) {
+ const float grad0 = srow[ox];
+
+ const int ix = offset0 + ox * s0;
+ const int iy = offset1 + oy * s1;
+
+ if (op == GGML_OP_POOL_MAX) {
+ float maxval = -FLT_MAX;
+ int kxmax = -1;
+ int kymax = -1;
+
+ for (int ky = 0; ky < k1; ++ky) {
+ if (iy + ky < 0 || iy + ky >= dst->ne[1]) {
+ continue;
+ }
+ const void * drowf = (const void *)(cdataf + dst->nb[1] * (iy + ky));
+ for (int kx = 0; kx < k0; ++kx) {
+ int j = ix + kx;
+ if (j < 0 || j >= dst->ne[0]) {
+ continue;
+ }
+
+ const float val = dst->type == GGML_TYPE_F32 ?
+ ((const float *) drowf)[j] : GGML_FP16_TO_FP32(((const ggml_fp16_t *) drowf)[j]);
+ if (val <= maxval) {
+ continue;
+ }
+
+ maxval = val;
+ kxmax = kx;
+ kymax = ky;
+ }
+ }
+
+ if (kxmax == -1 || kymax == -1) {
+ continue;
+ }
+
+ void * drow = (void *)(cdata + dst->nb[1] * (iy + kymax));
+ const int j = ix + kxmax;
+ if (dst->type == GGML_TYPE_F32) {
+ ((float *) drow)[j] += grad0;
+ } else {
+ ((ggml_fp16_t *) drow)[j] = GGML_FP32_TO_FP16(grad0 + GGML_FP16_TO_FP32(((const ggml_fp16_t *) drow)[j]));
+ }
+ } else if (op == GGML_OP_POOL_AVG) {
+ const float grad = grad0 / ka;
+
+ for (int ky = 0; ky < k1; ++ky) {
+ if (iy + ky < 0 || iy + ky >= dst->ne[1]) {
+ continue;
+ }
+ void * drow = (void *)(cdata + dst->nb[1] * (iy + ky));
+ for (int kx = 0; kx < k0; ++kx) {
+ int j = ix + kx;
+ if (j < 0 || j >= dst->ne[0]) {
+ continue;
+ }
+
+ if (dst->type == GGML_TYPE_F32) {
+ ((float *) drow)[j] += grad;
+ } else {
+ ((ggml_fp16_t *) drow)[j] += GGML_FP32_TO_FP16(grad);
+ }
+ }
+ }
+ } else {
+ GGML_ASSERT(false);
+ }
+ }
+ }
+
+ cdata += dst->nb[2];
+ cdataf += dst->nb[2];
+ splane += pa;
+ }
+}
+
// ggml_compute_forward_upscale
static void ggml_compute_forward_upscale_f32(
{
ggml_compute_forward_im2col(params, tensor);
} break;
+ case GGML_OP_IM2COL_BACK:
+ {
+ ggml_compute_forward_im2col_back_f32(params, tensor);
+ } break;
case GGML_OP_CONV_TRANSPOSE_2D:
{
ggml_compute_forward_conv_transpose_2d(params, tensor);
{
ggml_compute_forward_pool_2d(params, tensor);
} break;
+ case GGML_OP_POOL_2D_BACK:
+ {
+ ggml_compute_forward_pool_2d_back(params, tensor);
+ } break;
case GGML_OP_UPSCALE:
{
ggml_compute_forward_upscale(params, tensor);
src0->grad = ggml_add_or_set(ctx, src0->grad, tensor->grad, zero_table);
}
if (src1->grad) {
- src1->grad = ggml_add_or_set(ctx, src1->grad, tensor->grad, zero_table);
+ if (ggml_are_same_shape(src0, src1)) {
+ src1->grad = ggml_add_or_set(ctx, src1->grad, tensor->grad, zero_table);
+ } else {
+ src1->grad = ggml_add_or_set(ctx, src1->grad, ggml_repeat_back(ctx, tensor->grad, src1), zero_table);
+ }
}
} break;
case GGML_OP_ADD1:
GGML_ABORT("fatal error"); // TODO: not implemented
}
case GGML_OP_IM2COL:
+ {
+ if (src1->grad) {
+ const int32_t s0 = ggml_get_op_params_i32(tensor, 0);
+ const int32_t s1 = ggml_get_op_params_i32(tensor, 1);
+ const int32_t p0 = ggml_get_op_params_i32(tensor, 2);
+ const int32_t p1 = ggml_get_op_params_i32(tensor, 3);
+ const int32_t d0 = ggml_get_op_params_i32(tensor, 4);
+ const int32_t d1 = ggml_get_op_params_i32(tensor, 5);
+ const bool is_2D = ggml_get_op_params_i32(tensor, 6) == 1;
+
+ src1->grad = ggml_add_or_set(ctx,
+ src1->grad,
+ ggml_im2col_back(ctx, src0, tensor->grad, src1->ne, s0, s1, p0, p1, d0, d1, is_2D),
+ zero_table);
+ }
+ } break;
+ case GGML_OP_IM2COL_BACK:
{
GGML_ABORT("fatal error"); // TODO: not implemented
}
GGML_ABORT("fatal error"); // TODO: not implemented
}
case GGML_OP_POOL_2D:
+ {
+ if (src0->grad) {
+ const enum ggml_op_pool op = ggml_get_op_params_i32(tensor, 0);
+ const int32_t k0 = ggml_get_op_params_i32(tensor, 1);
+ const int32_t k1 = ggml_get_op_params_i32(tensor, 2);
+ const int32_t s0 = ggml_get_op_params_i32(tensor, 3);
+ const int32_t s1 = ggml_get_op_params_i32(tensor, 4);
+ const int32_t p0 = ggml_get_op_params_i32(tensor, 5);
+ const int32_t p1 = ggml_get_op_params_i32(tensor, 6);
+
+ src0->grad = ggml_add_or_set(ctx,
+ src0->grad,
+ ggml_pool_2d_back(ctx, tensor->grad, src0, op, k0, k1, s0, s1, p0, p1),
+ zero_table);
+ }
+ } break;
+ case GGML_OP_POOL_2D_BACK:
{
GGML_ABORT("fatal error"); // TODO: not implemented
}
void ggml_build_backward_expand(struct ggml_context * ctx, struct ggml_cgraph * gf, struct ggml_cgraph * gb, bool keep) {
GGML_ASSERT(gf->n_nodes > 0);
+ GGML_ASSERT(gf->grads);
// if we are keeping the gradient graph, we have to detach the gradient nodes from the original graph
if (keep) {
n_tasks = MIN(n_threads, ggml_nrows(node->src[0]));
} break;
case GGML_OP_IM2COL:
+ case GGML_OP_IM2COL_BACK:
case GGML_OP_CONV_TRANSPOSE_1D:
case GGML_OP_CONV_TRANSPOSE_2D:
{
} break;
case GGML_OP_POOL_1D:
case GGML_OP_POOL_2D:
+ case GGML_OP_POOL_2D_BACK:
{
n_tasks = 1;
} break;
const uint32_t type = tensor->type;
const uint32_t op = tensor->op;
+ const int32_t flags = tensor->flags;
fwrite(&type, sizeof(uint32_t), 1, fout);
fwrite(&op, sizeof(uint32_t), 1, fout);
+ fwrite(&flags, sizeof(int32_t), 1, fout);
for (int j = 0; j < GGML_MAX_DIMS; ++j) {
const uint64_t ne = tensor->ne[j];
const uint32_t type = tensor->type;
const uint32_t op = tensor->op;
+ const int32_t flags = tensor->flags;
fwrite(&type, sizeof(uint32_t), 1, fout);
fwrite(&op, sizeof(uint32_t), 1, fout);
+ fwrite(&flags, sizeof(int32_t), 1, fout);
for (int j = 0; j < GGML_MAX_DIMS; ++j) {
const uint64_t ne = tensor->ne[j];
}
}
}
+
+ // dump the data
+ // TODO: pad this to 32 byte boundary
+ if ((flags & GGML_TENSOR_FLAG_PARAM)) {
+ const size_t size = ggml_nbytes(tensor);
+
+ fwrite(tensor->data, sizeof(char), size, fout);
+ }
}
}
{
uint32_t type;
uint32_t op;
+ int32_t flags;
for (uint32_t i = 0; i < n_leafs; ++i) {
type = *(const uint32_t *) ptr; ptr += sizeof(type);
op = *(const uint32_t *) ptr; ptr += sizeof(op);
+ flags = *(const int32_t *) ptr; ptr += sizeof(flags);
int64_t ne[GGML_MAX_DIMS];
size_t nb[GGML_MAX_DIMS];
struct ggml_tensor * tensor = ggml_new_tensor(*ctx_eval, (enum ggml_type) type, GGML_MAX_DIMS, ne);
- tensor->op = (enum ggml_op) op;
+ tensor->op = (enum ggml_op) op;
+ tensor->flags = flags;
memcpy(tensor->name, ptr, GGML_MAX_NAME); ptr += GGML_MAX_NAME;
memcpy(tensor->op_params, ptr, GGML_MAX_OP_PARAMS); ptr += GGML_MAX_OP_PARAMS;
- tensor->data = (void *) ptr;
-
for (int j = 0; j < GGML_MAX_DIMS; ++j) {
tensor->nb[j] = nb[j];
}
- result->leafs[i] = tensor;
+ tensor->data = (void *) ptr; ptr += ggml_nbytes(tensor);
- ptr += ggml_nbytes(tensor);
+ result->leafs[i] = tensor;
fprintf(stderr, "%s: loaded leaf %u: '%16s', %9zu bytes\n", __func__, i, tensor->name, ggml_nbytes(tensor));
}
{
uint32_t type;
uint32_t op;
+ int32_t flags;
for (uint32_t i = 0; i < n_nodes; ++i) {
type = *(const uint32_t *) ptr; ptr += sizeof(type);
op = *(const uint32_t *) ptr; ptr += sizeof(op);
+ flags = *(const int32_t *) ptr; ptr += sizeof(flags);
enum ggml_op eop = (enum ggml_op) op;
result->nodes[i] = tensor;
+ // TODO tensor data is be duplicated due to ggml_new_tensor call above
+ if (flags & GGML_TENSOR_FLAG_PARAM) {
+ tensor->data = (void *) ptr; ptr += ggml_nbytes(tensor);
+ }
+
fprintf(stderr, "%s: loaded node %u: '%16s', %9zu bytes\n", __func__, i, tensor->name, ggml_nbytes(tensor));
}
}
struct ggml_context * ctx,
struct ggml_opt_params params,
struct ggml_tensor * f) {
+ GGML_ASSERT(f->grad && "ggml_set_param called for at least one parent tensor.");
+
bool free_ctx = false;
if (ctx == NULL) {
struct ggml_init_params params_ctx = {
ggml_opt_callback callback,
void * callback_data) {
+ GGML_ASSERT(f->grad && "ggml_set_param must be called for at least one ancestor");
+
// build forward + backward compute graphs
enum ggml_opt_result result = GGML_OPT_RESULT_OK;
void gguf_add_tensor(
struct gguf_context * ctx,
const struct ggml_tensor * tensor) {
+ GGML_ASSERT(tensor);
if (gguf_find_tensor(ctx, tensor->name) != -1) {
GGML_ABORT("duplicated tensor name");
}
#define _CRT_SECURE_NO_DEPRECATE // Disables ridiculous "unsafe" warnings on Windows
#include "ggml.h"
+#include <cfloat>
#include <cmath>
+#include <cstdint>
#include <cstdio>
#include <cstdlib>
#include <cassert>
+#include <initializer_list>
+#include <vector>
#if defined(_MSC_VER)
#pragma warning(disable: 4244 4267) // possible loss of data
int nargs,
float eps,
float max_error_abs,
- float max_error_rel) {
+ float max_error_rel,
+ std::vector<double> expected_vals) {
static int n_threads = -1;
if (n_threads < 0) {
// ggml_graph_dump_dot(gb, gf, "test-grad0-backward.dot");
for (int i = 0; i < nargs; ++i) {
+ bool all_g0_bad = true;
const int nelements = ggml_nelements(x[i]);
for (int k = 0; k < nelements; ++k) {
- // compute gradient using finite differences
+ // Calculate gradient numerically:
const float x0 = ggml_get_f32_1d(x[i], k);
const float xm = x0 - eps;
const float xp = x0 + eps;
const double f1 = ggml_get_f32_1d(f, 0);
const double g0 = (f0 - f1)/(2.0*(double) eps);
+ // The numerical calculation of the gradient fails around noncontinuities (e.g. 0 for ReLU).
+ // In such cases, provide a vector of expected values and skip the comparison for failed calculations.
+ if (!expected_vals.empty()) {
+ bool matches_any = false;
+ for (const double & ev : expected_vals) {
+ const double error_abs = std::fabs(g0 - ev);
+ if (error_abs > max_error_abs) {
+ continue;
+ }
+ const double error_rel = g0 != 0.0 ? fabs(g0 - ev)/fabs(g0) : 0.0;
+ if (error_rel > max_error_rel) {
+ continue;
+ }
+ matches_any = true;
+ break;
+ }
+ if (!matches_any) {
+ continue;
+ }
+ }
+ all_g0_bad = false;
+
ggml_set_f32_1d(x[i], k, x0);
// compute gradient using backward graph
const double g1 = ggml_get_f32_1d(x[i]->grad, k);
const double error_abs = fabs(g0 - g1);
- const double error_rel = g0 != 0 ? fabs(g0 - g1)/fabs(g0) : 0;
+ const double error_rel = g0 != 0.0 ? fabs(g0 - g1)/fabs(g0) : 0.0;
if (error_abs > max_error_abs || error_rel > max_error_rel) {
printf("%s: ndims=%d, i=%d, k=%d, x0=%f, xm=%f, xp=%f, f0=%f, f1=%f, g0=%f, g1=%f, eps=%f, error_abs=%f, error_rel=%f\n",
return false;
}
}
+ if (all_g0_bad) {
+ printf("%s: numerical calculation of the gradient failed for all values\n", op_name);
+ return false;
+ }
}
return true;
seed_iter = rand();
unsigned seed = rand();
- printf("test-grad0: iter:%d/%d\n", iter, niter);
+ printf("test-grad0: iter:%d/%d\n", (iter+1), niter);
struct ggml_context * ctx0 = ggml_init(params);
get_random_dims(ne, 4);
struct ggml_tensor * f = ggml_sum(ctx0, ggml_add(ctx0, x[0], x[1]));
- check_gradient("add f32", ctx0, x, f, ndims, nargs, 1e-3f, 2e-3f, 2e-3f);
+ check_gradient("add f32", ctx0, x, f, ndims, nargs, 1e-3f, 2e-3f, 2e-3f, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_add(ctx0, x[0], x[1]));
- check_gradient("add f16", ctx0, x, f, ndims, nargs, 1e-1f, 2e-1f, 2e-1f);
+ check_gradient("add f16", ctx0, x, f, ndims, nargs, 1e-1f, 2e-1f, 2e-1f, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_sub(ctx0, x[0], x[1]));
- check_gradient("sub", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f);
+ check_gradient("sub", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_mul(ctx0, x[0], x[1]));
- check_gradient("mul", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("mul", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_div(ctx0, x[0], x[1]));
- check_gradient("div", ctx0, x, f, ndims, nargs, 1e-3f, 1e-1f, 1e-1f);
+ check_gradient("div", ctx0, x, f, ndims, nargs, 1e-3f, 1e-1f, 1e-1f, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_sqr(ctx0, x[0]));
- check_gradient("sqr", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("sqr", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_sqrt(ctx0, x[0]));
- check_gradient("sqrt", ctx0, x, f, ndims, nargs, 1e-3f, 2e-2f, 1e-1f);
+ check_gradient("sqrt", ctx0, x, f, ndims, nargs, 1e-3f, 2e-2f, 1e-1f, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_log(ctx0, x[0]));
- check_gradient("log", ctx0, x, f, ndims, nargs, 1e-3f, INFINITY, 1e-1f);
+ check_gradient("log", ctx0, x, f, ndims, nargs, 1e-3f, INFINITY, 1e-1f, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, x[0]);
- check_gradient("sum", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f);
+ check_gradient("sum", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_sqr(ctx0, ggml_sum_rows(ctx0, x[0])));
- check_gradient("sum_rows", ctx0, x, f, ndims, nargs, 1e-3f, 1e-2f, INFINITY);
+ check_gradient("sum_rows", ctx0, x, f, ndims, nargs, 1e-3f, 1e-2f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_mean(ctx0, x[0]));
- check_gradient("mean", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f);
+ check_gradient("mean", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_argmax(ctx0, x[0]));
- check_gradient("argmax", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f);
+ check_gradient("argmax", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_sqr(ctx0, ggml_sub(ctx0, x[1], ggml_repeat(ctx0, x[0], x[1]))));
- check_gradient("repeat", ctx0, x, f, ndims, nargs, 1e-3f, 1e-2f, INFINITY);
+ check_gradient("repeat", ctx0, x, f, ndims, nargs, 1e-3f, 1e-2f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_sqr(ctx0, ggml_sub(ctx0, x[0], ggml_repeat_back(ctx0, x[1], x[0]))));
- check_gradient("repeat back", ctx0, x, f, ndims, nargs, 1e-3f, 1e-2f, INFINITY);
+ check_gradient("repeat back", ctx0, x, f, ndims, nargs, 1e-3f, 1e-2f, INFINITY, {});
}
}
- // abs (finite differences do not work)
- //{
- // const int nargs = 1;
+ // abs
+ {
+ const int nargs = 1;
- // for (int ndims = 1; ndims <= 2; ++ndims) {
- // for (int i = 0; i < nargs; ++i) {
- // x[i] = get_random_tensor_f32(ctx0, ndims, ne, -1.0f, 1.0f);
- // ggml_set_param(ctx0, x[i]);
- // }
+ for (int ndims = 1; ndims <= 4; ++ndims) {
+ for (int i = 0; i < nargs; ++i) {
+ x[i] = get_random_tensor_f32(ctx0, ndims, ne, -1.0f, 1.0f);
+ ggml_set_param(ctx0, x[i]);
+ }
- // struct ggml_tensor * f = ggml_sum(ctx0, ggml_abs(ctx0, x[0]));
+ struct ggml_tensor * f = ggml_sum(ctx0, ggml_abs(ctx0, x[0]));
- // check_gradient("abs", ctx0, x, f, ndims, nargs, 1e-3f, INFINITY, 1e-3f);
- // }
- //}
+ check_gradient("abs", ctx0, x, f, ndims, nargs, 1e-3f, INFINITY, 1e-3f, {-1.0, 1.0});
+ }
+ }
// sgn
{
struct ggml_tensor* f = ggml_sum(ctx0, ggml_sgn(ctx0, x[0]));
- check_gradient("sgn", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f);
+ check_gradient("sgn", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f, {0.0});
}
}
struct ggml_tensor* f = ggml_sum(ctx0, ggml_neg(ctx0, x[0]));
- check_gradient("neg", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f);
+ check_gradient("neg", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f, {});
}
}
struct ggml_tensor* f = ggml_sum(ctx0, ggml_step(ctx0, x[0]));
- check_gradient("step", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f);
+ check_gradient("step", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f, {0.0});
}
}
struct ggml_tensor* f = ggml_sum(ctx0, ggml_tanh(ctx0, x[0]));
- check_gradient("tanh", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f);
+ check_gradient("tanh", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f, {});
}
}
GGML_PRINT_DEBUG("testing: mul_mat, [%lld, %lld] (%d) * [%lld, %lld] (%d)\n", x[1]->ne[0], x[1]->ne[1], x[1]->n_dims, x[0]->ne[0], x[0]->ne[1], x[0]->n_dims);
- check_gradient("mul_mat", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("mul_mat", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
if (ndims == 2) {
// check_mat_mul does not support ndims > 2
check_mat_mul(m, x[1], x[0]);
struct ggml_tensor* f = ggml_sum(ctx0, ggml_elu(ctx0, x[0]));
- check_gradient("elu", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f);
+ check_gradient("elu", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f, {});
}
}
struct ggml_tensor* f = ggml_sum(ctx0, ggml_relu(ctx0, x[0]));
- check_gradient("relu", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("relu", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {0.0, 1.0});
}
}
struct ggml_tensor* f = ggml_sum(ctx0, ggml_gelu(ctx0, x[0]));
- check_gradient("gelu", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f);
+ check_gradient("gelu", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, 1e-3f, {});
}
}
#ifdef GGML_SILU_FP16
// due to GGML_SILU_FP16 the finite difference method will be slightly wrong -> increase error bounds.
- check_gradient("silu", ctx0, x, f, ndims, nargs, 1e-3f, 0.5, INFINITY);
+ check_gradient("silu", ctx0, x, f, ndims, nargs, 1e-3f, 0.5, INFINITY, {});
#else
- check_gradient("silu", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("silu", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
#endif
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_rms_norm(ctx0, x[0], 1e-6f));
- check_gradient("rms_norm", ctx0, x, f, ndims, nargs, 1e-4f, 1.0f, INFINITY);
+ check_gradient("rms_norm", ctx0, x, f, ndims, nargs, 1e-4f, 1.0f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_scale(ctx0, x[0], s));
- check_gradient("scale", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("scale", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_cpy(ctx0, x[0], x[1]));
- check_gradient("cpy f32", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("cpy f32", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_cpy(ctx0, x[0], x[1]));
- check_gradient("cpy f16", ctx0, x, f, ndims, nargs, 1e-1f, 1e-1f, INFINITY);
+ check_gradient("cpy f16", ctx0, x, f, ndims, nargs, 1e-1f, 1e-1f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_reshape(ctx0, x[0], x[1]));
- check_gradient("reshape", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("reshape", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_reshape(ctx0, x[0], x[1]));
- check_gradient("reshape", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("reshape", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_acc(ctx0, x[0], x[1], x[0]->nb[1], x[0]->nb[2], x[0]->nb[3], offset));
- check_gradient("acc 1d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("acc 1d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_acc(ctx0, x[0], x[1], x[0]->nb[1], x[0]->nb[2], x[0]->nb[3], offset));
- check_gradient("acc 2d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("acc 2d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_acc(ctx0, x[0], x[1], x[0]->nb[1], x[0]->nb[2], x[0]->nb[3], offset));
- check_gradient("acc 3d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("acc 3d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_acc(ctx0, x[0], x[1], x[0]->nb[1], x[0]->nb[2], x[0]->nb[3], offset));
- check_gradient("acc 4d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("acc 4d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_set_1d(ctx0, x[0], x[1], offset));
- check_gradient("set_1d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("set_1d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_set_2d(ctx0, x[0], x[1], x[1]->nb[1], offset));
- check_gradient("set_2d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("set_2d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_view_1d(ctx0, x[0], nelem, offset));
- check_gradient("view_1d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("view_1d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_view_2d(ctx0, x[0], ne2[0], ne2[1], nb2[1], offset));
- check_gradient("view_2d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("view_2d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_view_3d(ctx0, x[0], ne2[0], ne2[1], ne2[2], nb2[1], nb2[2], offset));
- check_gradient("view_3d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("view_3d", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
}
// sum requires contiguous tensor rows
struct ggml_tensor * f = ggml_sum(ctx0, ggml_cont(ctx0, ggml_permute(ctx0, x[0], ax0, ax1, ax2, ax3)));
- check_gradient("permute", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("permute", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
}
// sum requires contiguous tensor rows
struct ggml_tensor * f = ggml_sum(ctx0, ggml_cont(ctx0, ggml_transpose(ctx0, x[0])));
- check_gradient("transpose", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("transpose", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_get_rows(ctx0, x[0], x[1]));
- check_gradient("get_rows", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("get_rows", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
// diag_mask_inf
struct ggml_tensor * f = ggml_sum(ctx0, ggml_diag_mask_inf(ctx0, x[0], n_past));
- check_gradient("diag_mask_inf", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("diag_mask_inf", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
// diag_mask_zero
struct ggml_tensor * f = ggml_sum(ctx0, ggml_diag_mask_zero(ctx0, x[0], n_past));
- check_gradient("diag_mask_zero", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
+ check_gradient("diag_mask_zero", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, {});
}
// softmax
1.0f - eps),
ggml_new_f32(ctx0, eps))));
- check_gradient("softmax", ctx0, x, f, ndims, nargs, 1e-3f, 2e-1f, INFINITY);
+ check_gradient("softmax", ctx0, x, f, ndims, nargs, 1e-3f, 2e-1f, INFINITY, {});
// NOTE: softmax forward is computed using f16 table lookup instead of using actual expf, but backward assumes actual expf.
// this may result in different gradients too finite differences.
// when this test reports errors, first try to replace the table lookup with actual expf and test again to see if just that was the cause.
struct ggml_tensor * f = ggml_cross_entropy_loss(ctx0, x[0], x[1]);
- check_gradient("cross_entropy_loss", ctx0, x, f, ndims, nargs, 1e-4f, 1e-3f, INFINITY);
+ check_gradient("cross_entropy_loss", ctx0, x, f, ndims, nargs, 1e-4f, 1e-3f, INFINITY, {});
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_rope(ctx0, x[0], p, n_rot, mode));
GGML_PRINT_DEBUG("rope f32: n_past: %d n_rot: %d mode: %d\n", n_past, n_rot, mode);
- check_gradient("rope f32", ctx0, x, f, ndims, nargs, 1e-2f, 1e-3f, INFINITY);
+ check_gradient("rope f32", ctx0, x, f, ndims, nargs, 1e-2f, 1e-3f, INFINITY, {});
}
}
}
struct ggml_tensor * f = ggml_sum(ctx0, ggml_rope(ctx0, x[0], p, n_rot, mode));
GGML_PRINT_DEBUG("rope f16: n_past: %d n_rot: %d mode: %d\n", n_past, n_rot, mode);
- check_gradient("rope f16", ctx0, x, f, ndims, nargs, 1e-1f, 1e-1f, INFINITY);
+ check_gradient("rope f16", ctx0, x, f, ndims, nargs, 1e-1f, 1e-1f, INFINITY, {});
}
}
}
}
+ // im2col f32
+ {
+ srand(seed);
+ const int nargs = 1;
+ const int ndims = 4;
+
+ for (const bool is_2D : {false, true}) {
+ int64_t ne0[ndims];
+ int64_t ne1[ndims];
+ get_random_dims(ne0, ndims);
+ get_random_dims(ne1, ndims);
+
+ // // Ensure that the output is not zero-sized:
+ ne1[0] += 8;
+ ne1[1] += 8;
+
+ if (is_2D) {
+ ne1[2] = ne0[2];
+ } else {
+ ne1[1] = ne0[1];
+ ne0[3] = 1;
+ ne1[3] = 1;
+ }
+
+ // The order of arguments is swapped because the first tensor is only used for its shape.
+ x[1] = get_random_tensor_f16(ctx0, ndims, ne0, -1.0f, 1.0f);
+ x[0] = get_random_tensor_f32(ctx0, ndims, ne1, -1.0f, 1.0f);
+
+ ggml_set_param(ctx0, x[0]);
+
+ const int s0 = 1 + irand(2);
+ const int s1 = is_2D ? 1 + irand(2) : 0;
+ const int p0 = 0 + irand(2);
+ const int p1 = is_2D ? 0 + irand(2) : 0;
+ const int d0 = 1 + irand(2);
+ const int d1 = is_2D ? 1 + irand(2) : 0;
+
+ struct ggml_tensor * f = ggml_sum(ctx0, ggml_im2col(ctx0, x[1], x[0], s0, s1, p0, p1, d0, d1, is_2D, GGML_TYPE_F32));
+
+ GGML_PRINT_DEBUG("im2col f32: is_2D=%s, s0=%d, s1=%d, p0=%d, p1=%d, d0=%d, d1=%d\n", is_2D ? "yes" : "no", s0, s1, p0, p1, d0, d1);
+ check_gradient("im2col f32", ctx0, x, f, ndims, nargs, 1e-2f, 1e-3f, INFINITY, {});
+ }
+ }
+
+ // pool_2d f32
+ {
+ srand(seed);
+ const int nargs = 1;
+ const int ndims = 4;
+
+ for (const enum ggml_op_pool op : {GGML_OP_POOL_AVG, GGML_OP_POOL_MAX}) {
+ int64_t ne0[ndims];
+ get_random_dims(ne0, ndims);
+
+ ne0[0] += 8;
+ ne0[1] += 8;
+
+ x[0] = get_random_tensor_f32(ctx0, ndims, ne0, -1.0f, 1.0f);
+
+ ggml_set_param(ctx0, x[0]);
+
+ const int k0 = 2 + irand(2);
+ const int k1 = 2 + irand(2);
+ const int s0 = 2 + irand(2);
+ const int s1 = 2 + irand(2);
+ const int p0 = 0 + irand(2);
+ const int p1 = 0 + irand(2);
+
+ struct ggml_tensor * f = ggml_sum(ctx0, ggml_pool_2d(ctx0, x[0], op, k0, k1, s0, s1, p0, p1));
+
+ GGML_PRINT_DEBUG("ggml_pool_2d f32: op=%s k0=%d, k1=%d, s0=%d, s1=%d, p0=%d, p1=%d\n",
+ op == GGML_OP_POOL_MAX ? "max" : "avg", k0, k1, s0, s1, p0, p1);
+ std::vector<double> expected_vals;
+ if (op == GGML_OP_POOL_MAX) {
+ expected_vals.push_back(0.0);
+ expected_vals.push_back(1.0);
+ }
+ check_gradient("ggml_pool_2d f32", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY, expected_vals);
+ }
+ }
+
// flash_attn f32
// TODO: adapt to ggml_flash_attn_ext() changes
//{
// struct ggml_tensor * f = ggml_sum(ctx0, ggml_flash_attn(ctx0, x[0], x[1], x[2], (masked == 0)));
- // check_gradient("flash_attn f32", ctx0, x, f, ndims, nargs, 1.5e-4f, 1e-3f, INFINITY);
+ // check_gradient("flash_attn f32", ctx0, x, f, ndims, nargs, 1.5e-4f, 1e-3f, INFINITY, {});
// }
// }
// }